 做 RAG、搭知识库、喂文档给 AI——这几件事有一个共同的起点:你得先把 PDF 变成机器能读的结构化数据。
做 RAG、搭知识库、喂文档给 AI——这几件事有一个共同的起点:你得先把 PDF 变成机器能读的结构化数据。
现实是,PDF 恰恰是最难搞的格式。学术论文里混合着公式和表格,财务报表有跨页合并单元格,扫描件需要 OCR,多栏排版要还原阅读顺序。传统工具(pdfplumber、PyMuPDF、Tesseract)各自能解决一部分问题,但拼在一起总是差一口气:表格拆了、公式丢了、顺序乱了。
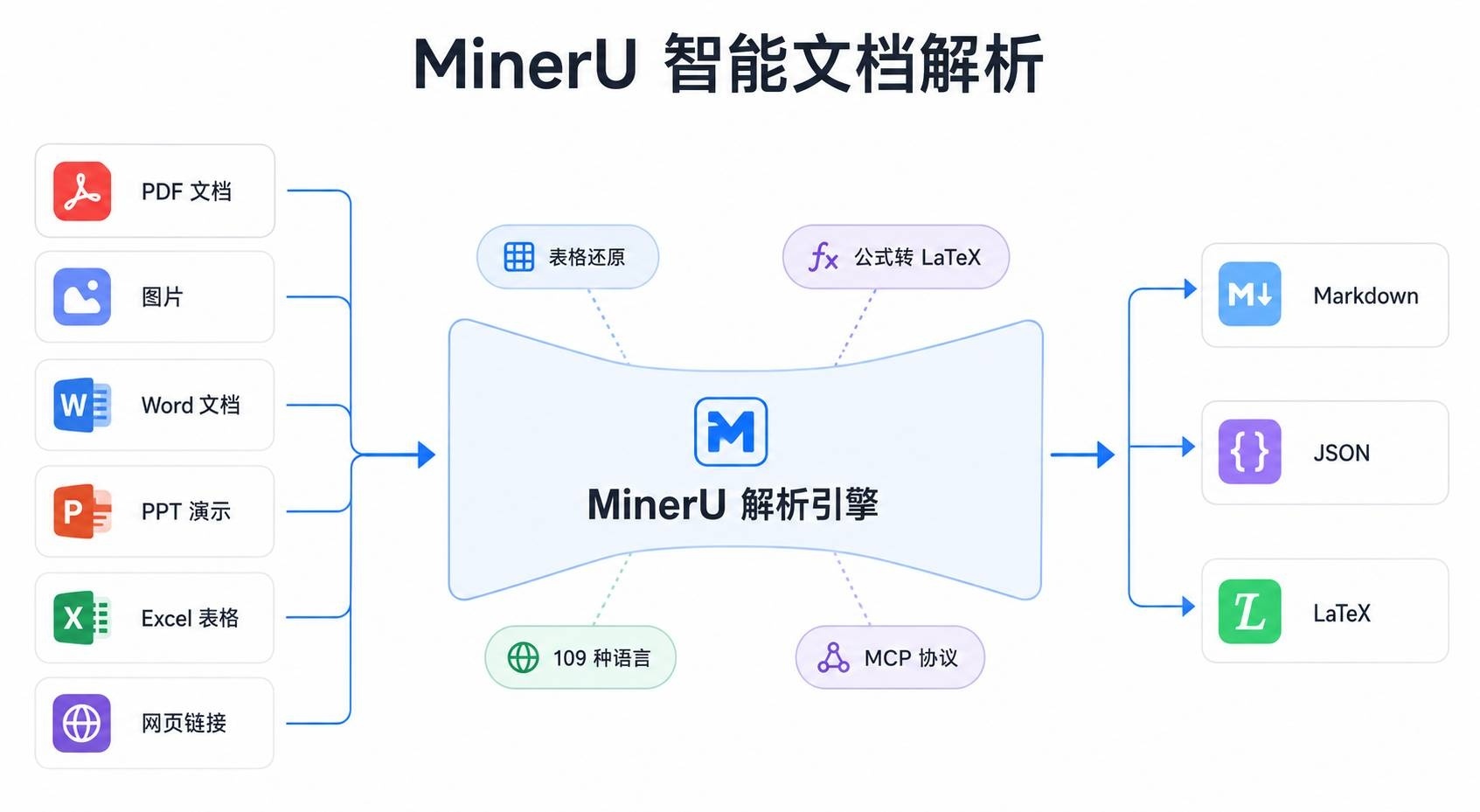
MinerU 是上海人工智能实验室 OpenDataLab 团队开源的文档解析工具,登顶过 GitHub Trending。它把 PDF、Word、PPT、Excel、图片、网页这些复杂文档,一次性转成干净的 Markdown、JSON 或 LaTeX——表格还原成 HTML,公式转成 LaTeX,阅读顺序自动排列。
项目诞生于 InternLM(书生·浦语)大模型预训练过程,最初用来解决科研文献里的符号转换问题。最新版本 3.1.0(2026 年 4 月发布),许可证从 AGPLv3 切换到基于 Apache 2.0 的自定义许可,商业使用门槛大幅降低。
核心能力
全格式输入
MinerU 支持六种输入格式:
- PDF 文档(文本型、扫描件、乱码 PDF 均可)
- 图片(JPG、PNG 等)
- Word 文档(.docx)——原生解析,不需要先转 PDF
- PowerPoint(.pptx)
- Excel(.xlsx)
- 网页 URL
输出三种格式:Markdown、JSON、LaTeX。其中 JSON 按阅读顺序排序,可以直接喂给 RAG。
表格智能还原
这是 MinerU 区别于其他解析工具的关键能力之一。它能处理:
- 旋转表格——表格在页面上是歪的,输出是正的
- 跨页表格——一个表格跨了两页,输出是一个完整的表
- 合并单元格——复杂的表头结构,输出是标准 HTML 或 Markdown 表格
输出格式支持 CSV、HTML、Markdown,可以直接接入下游数据处理流程。
公式精准转换
长公式、多行公式、嵌套数学结构,MinerU 都能识别并转换为 LaTeX 或 MathML 格式。这对科研类文档和数理大模型的训练数据准备来说,是刚需。
109 种语言 OCR
自动检测扫描件和乱码 PDF,启用 OCR 模式。支持 109 种语言的文字识别,包括中英日韩、阿拉伯语、印地语等。
化学论文解析
MinerU 与 A4Chemistry 合作,提供专业级化学文献解析:分子结构图识别(SOTA 性能)、化学反应过程提取、跨图片和文本的全局分子关联。这是大多数文档解析工具完全不具备的能力。
Agent 生态原生集成
MinerU 原生支持 MCP 协议,可以直接接入 Cursor、Claude Desktop、Windsurf 等 AI 编码工具。同时原生集成 LangChain、LlamaIndex、Dify、FastGPT、RAGFlow 等 RAG 框架。有 Python、Go、TypeScript 三种 SDK,以及 REST API 和 CLI。
技术架构
MinerU 采用 VLM(视觉语言模型)+ OCR 双引擎架构:
| 推理后端 | 精度(OmniDocBench v1.6) | 特点 | 硬件需求 |
|---|---|---|---|
| pipeline | 85+ | 快速稳定,无幻觉,支持纯 CPU | 4GB 显存或纯 CPU |
| vlm-engine | 95+ | 高精度,支持 vLLM/LMDeploy | 8GB 显存,需要 GPU |
| hybrid-engine | 95+ | 高精度 + 原生文本提取,低幻觉 | 8GB 显存,需要 GPU |
三种后端的取舍很清楚:追求速度和低资源消耗用 pipeline,追求精度用 VLM,两者都要用 hybrid。
VLM 主模型是团队自研的 MinerU2.5-Pro-2604-1.2B,专门针对文档理解任务训练。pipeline 后端在纯 CPU 环境也能跑,最低 16GB 内存就够。
解析流程分四个阶段:
文档输入
↓
分类预处理(检测文档类型、乱码、扫描件)
↓
模型解析(布局检测 + 公式检测 + OCR)
↓
管线处理(排序、去噪、结构化输出)
↓
输出 Markdown / JSON / LaTeX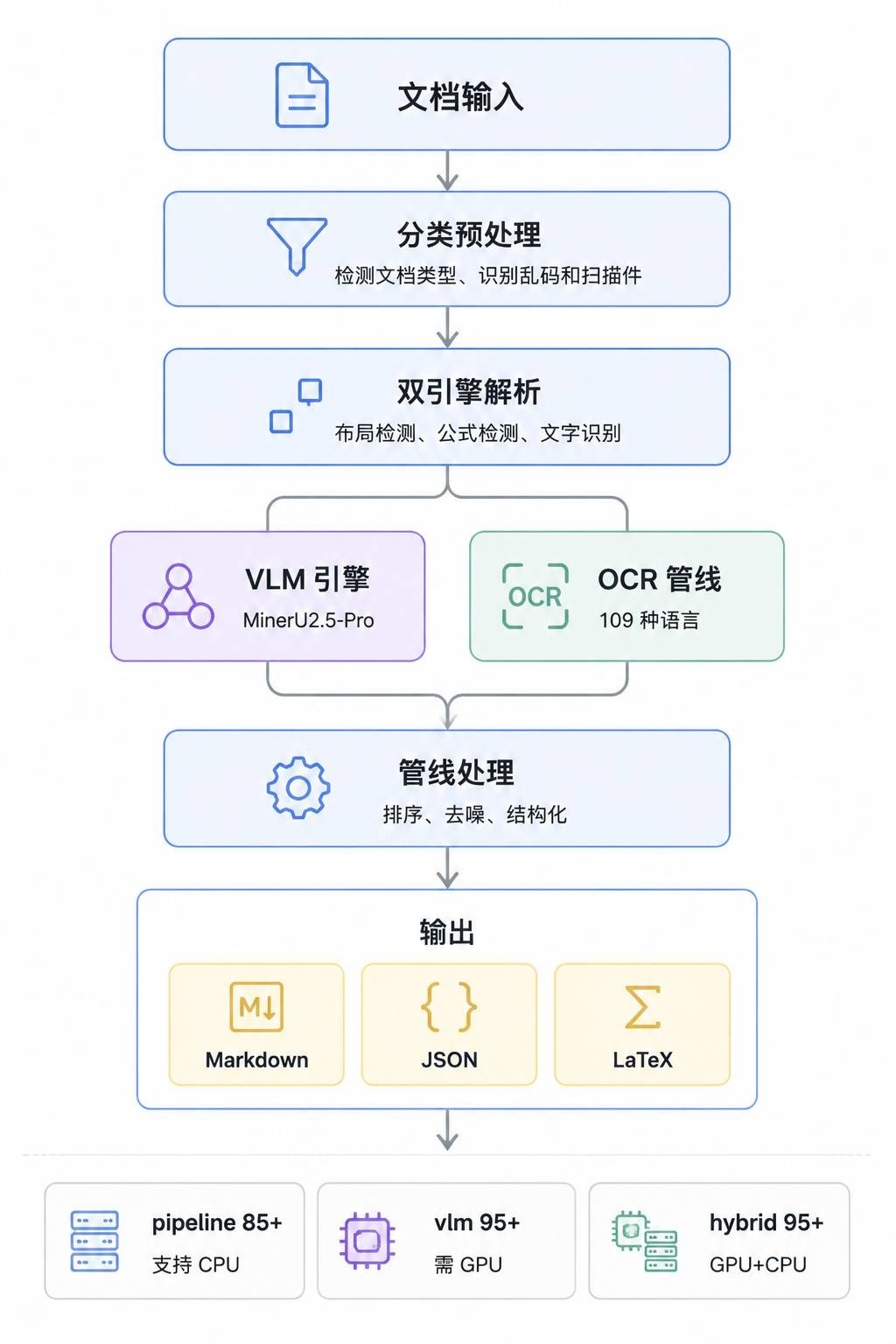
怎么用
MinerU 提供四种使用方式,从零代码到完全私有化部署都有覆盖。
在线使用
最简单的方式,打开 mineru.net,注册登录即可。功能和桌面客户端完全一致,适合不想折腾部署的用户。
也可以在 ModelScope 或 HuggingFace 上体验 Gradio Demo,不需要登录,只有核心解析功能。
API 调用
MinerU 提供 RESTful API,支持同步和异步两种模式:
- 同步接口:
POST /file_parse,适合单文件快速解析 - 异步接口:
POST /tasks,支持任务提交、状态查询、结果获取
有 Python SDK 可以直接 pip 安装。适合需要批量处理文档、或者要把解析能力集成到自己产品里的开发者。
桌面客户端
提供 Windows 和 macOS 桌面客户端,图形界面操作,不需要敲命令行。功能和在线版一致,但数据在本地处理,适合有数据合规要求的场景。
私有化部署
最灵活的方式,适合企业级场景:
# pip 安装
pip install uv
uv pip install -U "mineru[all]"
# 一行命令解析
mineru -p input.pdf -o output/也支持 Docker 部署和源码编译。生产环境推荐搭配 mineru-router 做多 GPU 部署和自动负载均衡。
MinerU 已适配 10+ 款国产 AI 芯片:昇腾、寒武纪、燧原、壁仞、摩尔线程、昆仑芯、天数智芯、海光、沐曦、平头哥。需要国产化部署的环境也能用。
资源与链接
- 官方网站:mineru.net
- GitHub 仓库:github.com/opendatalab/MinerU
- API 文档:mineru.net/apiManage/docs
- 在线体验:mineru.net/OpenSourceTools/Extractor
- ModelScope Demo:modelscope.cn/studios/OpenDataLab/MinerU
- HuggingFace Demo:huggingface.co/spaces/opendatalab/MinerU
- 常见问题:FAQ