 你的 Skill 写不好,不是因为指令太简单,而是因为 description 写得太笼统。
你的 Skill 写不好,不是因为指令太简单,而是因为 description 写得太笼统。
这是 Anthropic 在一份 33 页的官方 Skill 构建指南中揭示的最关键发现(PDF 下载链接见文末)。这份指南发布于 2026 年 1 月,大多数人甚至不知道它的存在。但其中关于 Skill 触发机制的洞察,直接解释了为什么你的 Skill 总是不灵。
本文从中提取了 7 个最关键的知识点。读完之后,你将知道:为什么 Skill 不触发(以及为什么该触发时不触发)、如何写一个精确触发的 description、以及 15 分钟内构建可用 Skill 的完整路径。
为什么 90% 的 Skill 都写错了
先说一个反直觉的事实:大多数 Skill 失败的根本原因不是指令写得差,而是 description 写得像"简介"。
Anthropic 的工程博客明确指出:description 字段是 Claude 决定是否加载 Skill 的唯一信号。它出现在系统提示中,Claude 凭它判断"现在该不该用这个 Skill"。
但大多数人把它当成了功能说明:
# 太模糊 — Claude 根本不知道什么时候该用它
description: 帮助处理项目。
# 缺少触发条件 — 写得再华丽也没用
description: 创建复杂的多页文档系统。
# 纯技术视角 — 没有用户会这样提问
description: 实现带有层级关系的项目实体模型。这些写法的共同问题是:没有告诉 Claude 用户会说什么话、在什么场景下、想要什么结果。 description 不是写给人看的介绍,是写给 Claude 的触发协议。
Anthropic 给出的正确公式是:
[做什么] + [什么时候用] + [关键能力]
也就是说,description 必须同时包含三件事:这个 Skill 干什么、用户会怎么触发它、它能处理哪些具体场景。缺一个都不行。
Skill 到底是什么?
在深入之前,先用三句话说清楚 Skill 的本质:
- Skill 是一个文件夹,核心是 SKILL.md(Markdown + YAML),配合可选的 scripts/、references/、assets/ 子目录。不需要编程,用自然语言就能写。
- Skill 解决的核心问题是"每次对话都从零开始"。传统 AI 对话中,你每次都要重新解释偏好、流程、规范。Skill 让这些知识变成一次编写、永久可用的"肌肉记忆"。
- Skill 在 Claude.ai、Claude Code 和 API 三端通用。创建一次,到处运行。前提是环境支持 Skill 所需的依赖。
文件结构非常简单:
your-skill-name/
├── SKILL.md # 必须 — 核心指令文件(大小写敏感)
├── scripts/ # 可选 — 可执行代码(Python、Bash 等)
├── references/ # 可选 — 参考文档(按需加载)
└── assets/ # 可选 — 模板、字体、图标等几个容易踩坑的命名规则:
- 文件夹名必须用 kebab-case:
my-cool-skill✅,My Cool Skill❌ - 文件名必须精确为
SKILL.md(skill.md、SKILL.MD都不行) - 文件夹内禁止放 README.md
description 字段:一个决定成败的 YAML 属性行
如果说官方指南里有一个"如果你只记住一件事"的核心,那就是:description 字段的写法决定了你的 Skill 能不能被找到。
这个字段必须满足以下条件:
| 要求 | 说明 |
|---|---|
| 同时包含"做什么"和"什么时候用" | 缺一不可 |
| 包含用户实际会说的触发短语 | 越具体,触发越可靠 |
| 提及相关文件类型(如适用) | 帮助 Claude 更精确匹配 |
| 不超过 1024 字符 | 硬性限制 |
不含 XML 标签(< >) |
安全限制 |
| 不含"claude"或"anthropic" | 保留字 |
来看三个好的 description 示例(以下改写自 Anthropic 官方示例):
# 好 — 具体 + 触发短语 + 文件类型
description: 分析 Figma 设计文件并生成开发者交接文档。当用户上传 .fig 文件、
要求"设计规格"、"组件文档"或"设计转代码交接"时使用。
# 好 — 包含明确的使用场景和用户会说的话
description: 管理 Linear 项目工作流,包括冲刺规划、任务创建和状态跟踪。
当用户提到"冲刺"、"Linear 任务"、"项目规划"或要求"创建工单"时使用。
# 好 — 清晰的价值主张 + 多个触发短语
description: PayFlow 端到端客户入驻工作流。处理账户创建、支付设置和订阅管理。
当用户说"入驻新客户"、"设置订阅"或"创建 PayFlow 账户"时使用。注意它们的共同特征:每个都包含用户真正会说的原话。这不是写简介,是写触发协议。
如果你的 Skill 触发过多(加载了不该加载的场景),还可以在 description 中加入负向排除:
description: CSV 文件的高级数据分析。用于统计建模、回归分析、聚类分析。
不要用于简单的数据探索(请使用 data-viz skill)。三层加载:餐厅菜单的智慧
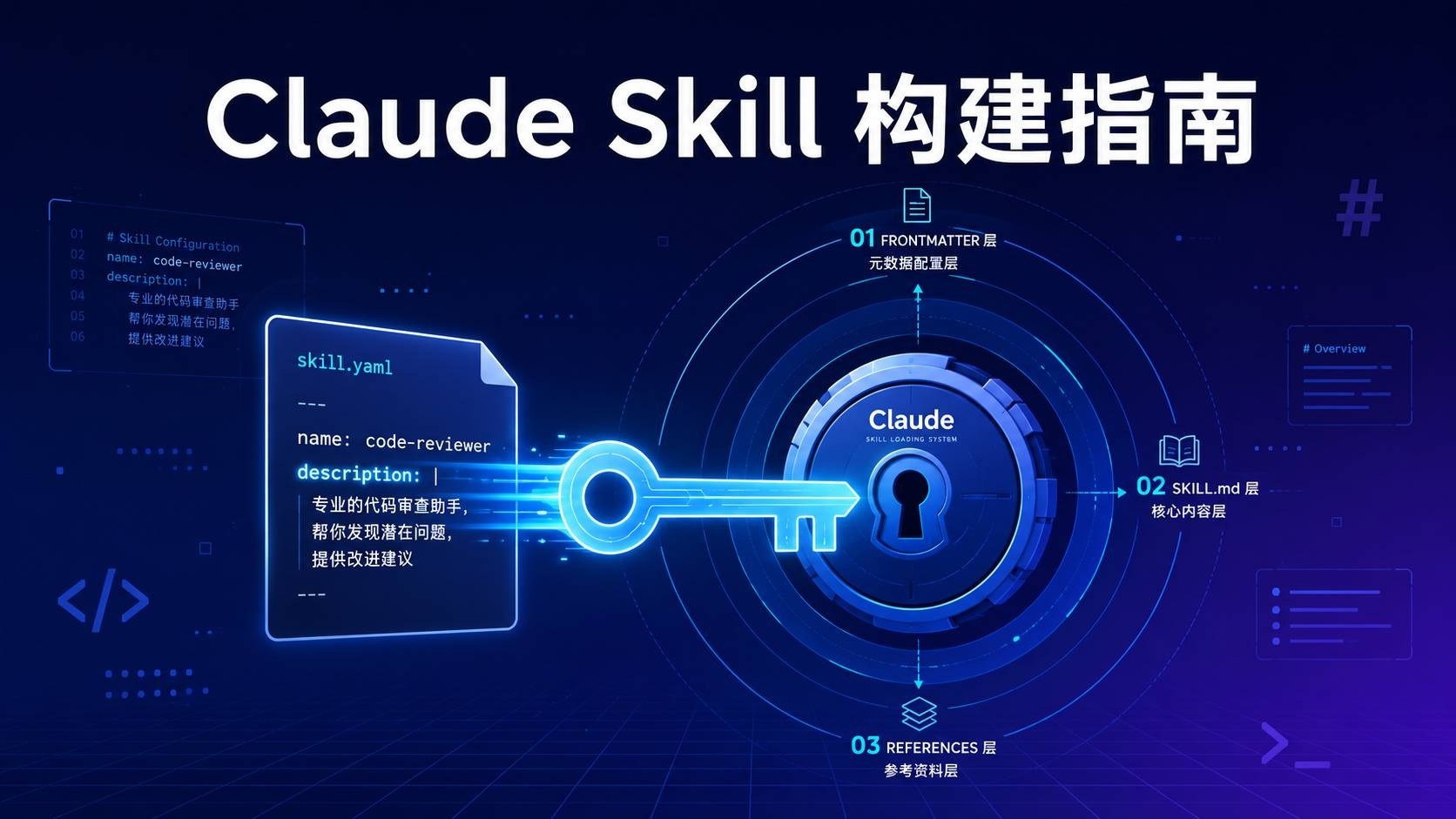
Skill 的加载不是"全部塞进去"或"什么都不加载",而是一个精心设计的三层渐进系统。Anthropic 把它叫做 Progressive Disclosure。
理解这个机制的最好方式是类比一家餐厅:
| 层级 | 内容 | 加载时机 | 餐厅类比 |
|---|---|---|---|
| 第一层 | YAML frontmatter(name + description) | 始终在系统提示中 | 菜单封面 — 告诉你有什么菜系 |
| 第二层 | SKILL.md 正文(完整指令) | 当 Claude 判断 Skill 相关时 | 完整菜单 — 你坐下了才给你看 |
| 第三层 | references/、scripts/、assets/ | 只有当需要具体内容时 | 后厨食材 — 你点了菜才去拿 |
这个设计有一个重要含义:你的 description(第一层)必须在极短的文字中精确传达"这个 Skill 能做什么",因为 Claude 仅凭它来决定是否加载第二层。如果 description 太模糊,Claude 会跳过你的 Skill;如果太宽泛,Claude 会在不该加载时也加载。
这也是为什么 Anthropic 说 description 是"最重要的部分"——它是整个三层系统的守门员。
从 token 经济学的角度看,这个设计非常聪明:
- 第一层每个 Skill 只占几十个 token(始终加载)
- 第二层按需加载,只在相关时才消耗 token
- 第三层只在执行过程中按需读取,进一步节省上下文
官方建议:SKILL.md 控制在 5000 字以内,详细文档移到 references/ 中。
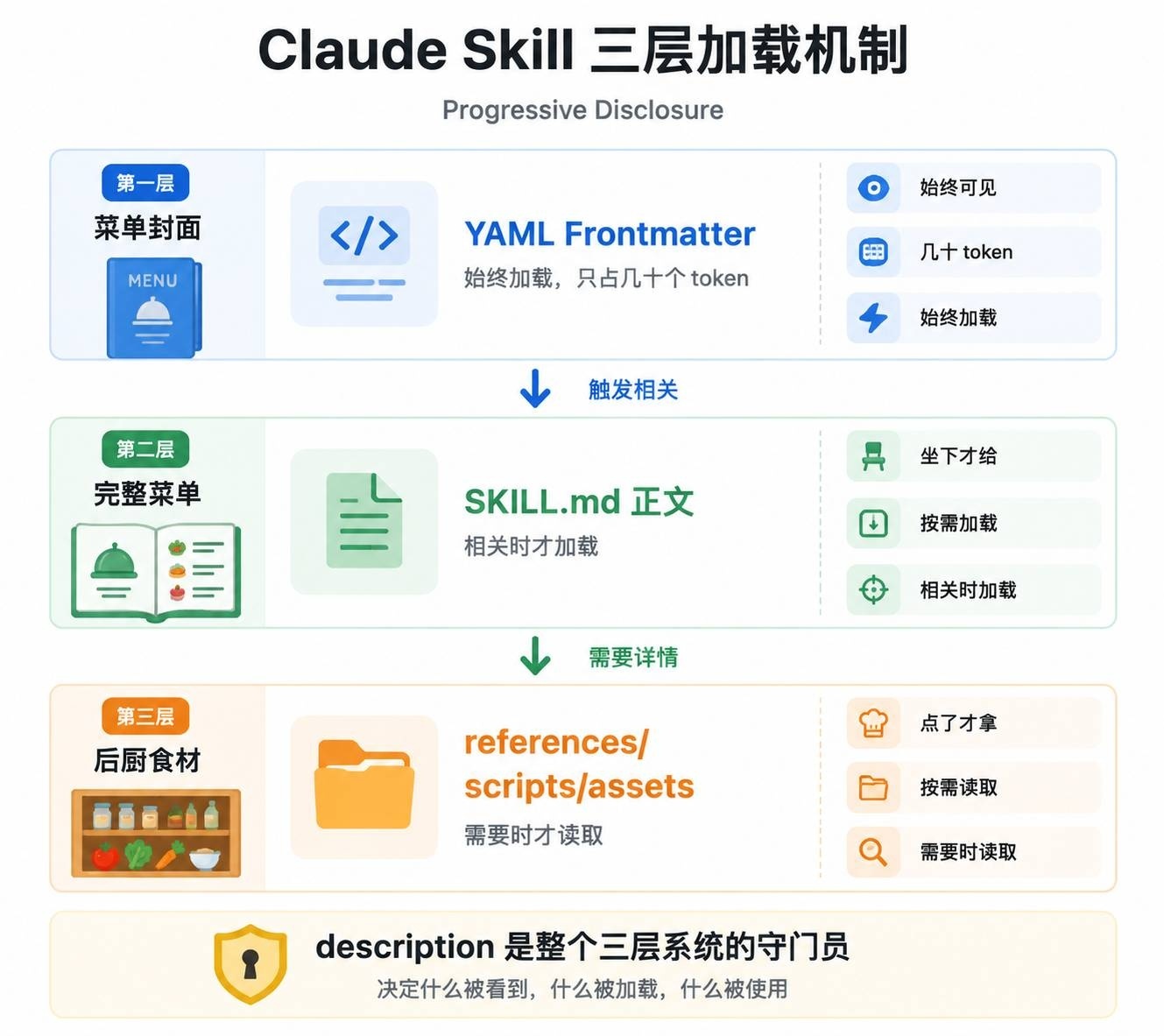
三种值得构建的 Skill 类型
Anthropic 从大量实践中总结了三种最有价值的 Skill 类型。你不需要全做,选一个最适合你的场景就行。
类型一:文档/资产创建型
一句话:让 Claude 每次都按你的方式产生东西。
适合场景:创建一致的文档、演示文稿、设计、代码,格式完全符合你的要求。
核心技巧:
- 嵌入样式指南和品牌标准
- 输出前有质量检查清单
- 不需要外部工具,利用 Claude 内置能力
官方实例:frontend-design skill — "Create distinctive, production-grade frontend interfaces with high design quality."
类型二:工作流自动化型
一句话:让 Claude 遵循你的多步骤流程,无需每次重新告知。
适合场景:多步骤流程、跨工具协调、需要一致方法论的复杂任务。
Anthropic 归纳了五大工作流模式:
| 模式 | 核心思路 | 适用场景 |
|---|---|---|
| 顺序编排 | Step 1 → Step 2 → Step 3,有依赖和验证 | 客户注册、发布流程 |
| 多 MCP 协调 | 跨多个服务的阶段式协调 | 设计→存储→任务→通知 |
| 迭代精炼 | 初稿 → 质量检查 → 改进 → 再验证 | 报告生成、内容创作 |
| 上下文选择 | 根据条件选择不同工具 | 智能文件存储路由 |
| 领域智能 | 嵌入专业知识,行动前先合规 | 金融合规、法律审查 |
类型三:MCP 增强型
一句话:教 Claude 如何正确使用你连接的工具。
这是最有杠杆效应的类型。Anthropic 用了一个精妙的类比:
MCP 是专业厨房(提供工具、食材和设备),Skill 是菜谱(提供步骤和最佳实践)。
两者组合才完整。看看对比:
| 没有 Skill | 有 Skill |
|---|---|
| 用户连接了 MCP 但不知道下一步做什么 | 预构建工作流自动激活 |
| 大量"怎么用你的集成做 X"的客服工单 | 一致、可靠的工具使用 |
| 每次对话从头开始 | 最佳实践嵌入每次交互 |
| 用户归咎于连接器(实际是工作流指导问题) | 更低的学习曲线 |
对 MCP 开发者而言,为你的 MCP 服务器创建配套 Skill,是把"工具连接"升级为"完整解决方案"的关键一步。
五个最常见的失败模式和修复方法
Anthropic 在指南中详细列出了常见的失败场景。以下是五个最频繁出现的问题及对应的修复方法。
失败 1:Skill 不触发
表现:Skill 从不自动加载,用户需要手动启用。
根因:description 太模糊或缺少触发短语。
修复:
- 检查是否写成了"帮助处理项目"这种空话
- 加入用户实际会说的原话作为触发短语
- 提及相关文件类型(如果有)
- 调试方法:直接问 Claude "When would you use the [skill name] skill?",它会引用 description,你就能看到缺了什么
失败 2:Skill 触发太频繁
表现:不相关的查询也触发你的 Skill,用户开始禁用它。
修复:
- 在 description 中加入负向排除("Do NOT use for...")
- 缩小范围("Processes PDF legal documents" 而不是 "Processes documents")
- 明确限定场景("for e-commerce payment workflows, not for general financial queries")
失败 3:指令被忽略
表现:Skill 加载了但 Claude 不按指令执行。
修复:
- 指令太冗长?精简为编号列表和要点,控制在 5000 字以内
- 关键指令埋在深处?用
## Critical或## Important放在最前面 - 语言太模糊?把"validate things properly"改成具体的三步检查清单
- Claude 太懒?加一句 "Quality is more important than speed. Do not skip validation steps."
失败 4:响应变慢
表现:Skill 加载后响应速度明显下降。
修复:
- SKILL.md 太大?把详细文档移到 references/,SKILL.md 只保留核心指令
- 同时启用了太多 Skill?评估是否超过 20-50 个,考虑按场景选择性启用
- 所有内容都内联?改用链接引用,利用第三层按需加载
失败 5:上传失败
表现:上传时报错 "Could not find SKILL.md" 或 "Invalid frontmatter"。
修复:
- 确认文件名是精确的
SKILL.md(大小写敏感) - 检查 YAML 格式:必须有
---分隔符,引号必须闭合 - 文件夹名不含空格和大写字母
从零开始的 15 分钟实战路径
Anthropic 在指南中说了一句很有分量的话:
"我们观察到最有效的 Skill 创建者,都是先让 Claude 在一个困难任务上成功,然后把成功的方法提取成 Skill。"
这给了我们一个清晰的行动路径:
第一步:选定一个重复工作流(5 分钟)
选择你不断重复的一个任务。不要贪心,一次只做一个。好的候选:
- 每次都要重复解释的文档格式
- 固定的多步骤操作流程
- 经常出错的工具使用场景
第二步:用 skill-creator 生成初版(5 分钟)
Claude 内置了一个叫 skill-creator 的元技能,专门帮你创建 Skill。直接对 Claude 说:
"Use the skill-creator skill to help me build a skill for [你的场景]"
它会:
- 自动生成格式正确的 SKILL.md(含 frontmatter)
- 建议触发短语和结构
- 标记常见问题(模糊描述、缺失触发、结构问题)
第三步:测试并迭代(5 分钟)
重点测试两件事:
触发测试:
- 说出应该触发的短语 — Skill 加载了吗?
- 换个说法再说一遍 — 还是能触发吗?
- 说一句不相关的话 — 没有误触发吧?
功能测试:
- Skill 执行后,结果符合预期吗?
- 有没有步骤出错或被跳过?
- 连续跑 3-5 次,结果一致吗?
如果触发不足,在 description 中加更多触发短语和关键词。如果触发过多,加负向排除。如果执行有问题,改进指令的具体性和错误处理。
发布渠道
测试通过后,你可以通过以下方式使用和分享:
- 个人使用:Claude.ai → Settings → Capabilities → Skills → 上传 ZIP
- Claude Code:放入 skills 目录即可
- 组织部署:管理员可 workspace 级别部署,自动更新
- 社区分享:GitHub 托管 + 清晰 README + 使用示例
写在最后:Skill 是你和 Claude 之间的协议,不是提示词
Skill 不是提示词工程的升级版。它是一套有严格架构的指令系统,核心是精确的触发协议和渐进式的信息加载。
回过头看,写好 Skill 的关键就三件事:
- 把 description 当触发协议写,不是当简介写。包含"做什么 + 什么时候用 + 关键能力"。
- 利用三层加载机制,SKILL.md 只放核心指令,详细内容放到 references/ 中。
- 先跑起来再迭代,用 skill-creator 生成初版,在真实使用中打磨。
掌握这三个机制,你就掌握了把 Claude 从"搜索引擎"变成"个人 AI 系统"的钥匙。
如果你读完这篇文章还觉得不够,完整 33 页指南的 PDF 在这里:The Complete Guide to Building Skills for Claude。官方示例 Skill 仓库在 GitHub anthropics/skills。