 火宝短剧(Huobao Drama) 是一个开源的 AI 短剧自动化生产平台。你给它一句话或一段小说文本,它自动走完「剧本改写 → 角色提取 → 分镜拆解 → AI 绘图 → AI 视频 → TTS 配音 → FFmpeg 合成」整条链路,输出完整的短剧视频。传统短剧制作需要编剧、角色设计、分镜绘制、配音、剪辑 5 个角色协作,一部 10 集短剧从策划到成片通常要 2-4 周。火宝短剧把这个流程压缩到 AI 全自动完成。不过要提前说一句:AI 生成的视频在画面清晰度和连贯性上还达不到电影级水准,拿来做短视频平台的竖屏短剧、快速验证创意是够用的,但如果你要追求精良画面,这个工具目前还做不到。另外项目的部署需要用命令行,纯小白可能会有点吃力。
火宝短剧(Huobao Drama) 是一个开源的 AI 短剧自动化生产平台。你给它一句话或一段小说文本,它自动走完「剧本改写 → 角色提取 → 分镜拆解 → AI 绘图 → AI 视频 → TTS 配音 → FFmpeg 合成」整条链路,输出完整的短剧视频。传统短剧制作需要编剧、角色设计、分镜绘制、配音、剪辑 5 个角色协作,一部 10 集短剧从策划到成片通常要 2-4 周。火宝短剧把这个流程压缩到 AI 全自动完成。不过要提前说一句:AI 生成的视频在画面清晰度和连贯性上还达不到电影级水准,拿来做短视频平台的竖屏短剧、快速验证创意是够用的,但如果你要追求精良画面,这个工具目前还做不到。另外项目的部署需要用命令行,纯小白可能会有点吃力。
本地开发部署(推荐想体验和改代码的人)
如果你想在本地跑起来看看效果,或者想改代码二次开发,用这个方式。
环境要求
| 软件 | 版本 | 说明 |
|---|---|---|
| Node.js | 20+ | 前后端运行环境 |
| npm | 9+ | 包管理 |
| FFmpeg | 4.0+ | 视频合成(必需) |
| Git | 任意 | 克隆项目 |
安装 FFmpeg(如果本地没有):
macOS:
brew install ffmpegUbuntu/Debian:
sudo apt update && sudo apt install ffmpegWindows:从 FFmpeg 官网 下载,解压后把 bin 目录加入系统 PATH。
验证:ffmpeg -version,看到版本号即可。
安装步骤
- 克隆项目:
git clone https://github.com/chatfire-AI/huobao-drama.git
cd huobao-drama- 安装后端依赖:
cd backend && npm install- 安装前端依赖:
cd ../frontend && npm install- 复制配置文件:
cp configs/config.example.yaml configs/config.yaml- 启动后端(终端 1):
cd backend
npm run dev后端 API 跑在 http://localhost:5678。
- 启动前端(终端 2):
cd frontend
npm run dev前端跑在 http://localhost:3012,自动代理 /api 和 /static 到后端。
- 打开
http://localhost:3012,看到界面就成功了。
数据库表在首次启动时自动创建,不需要手动操作。
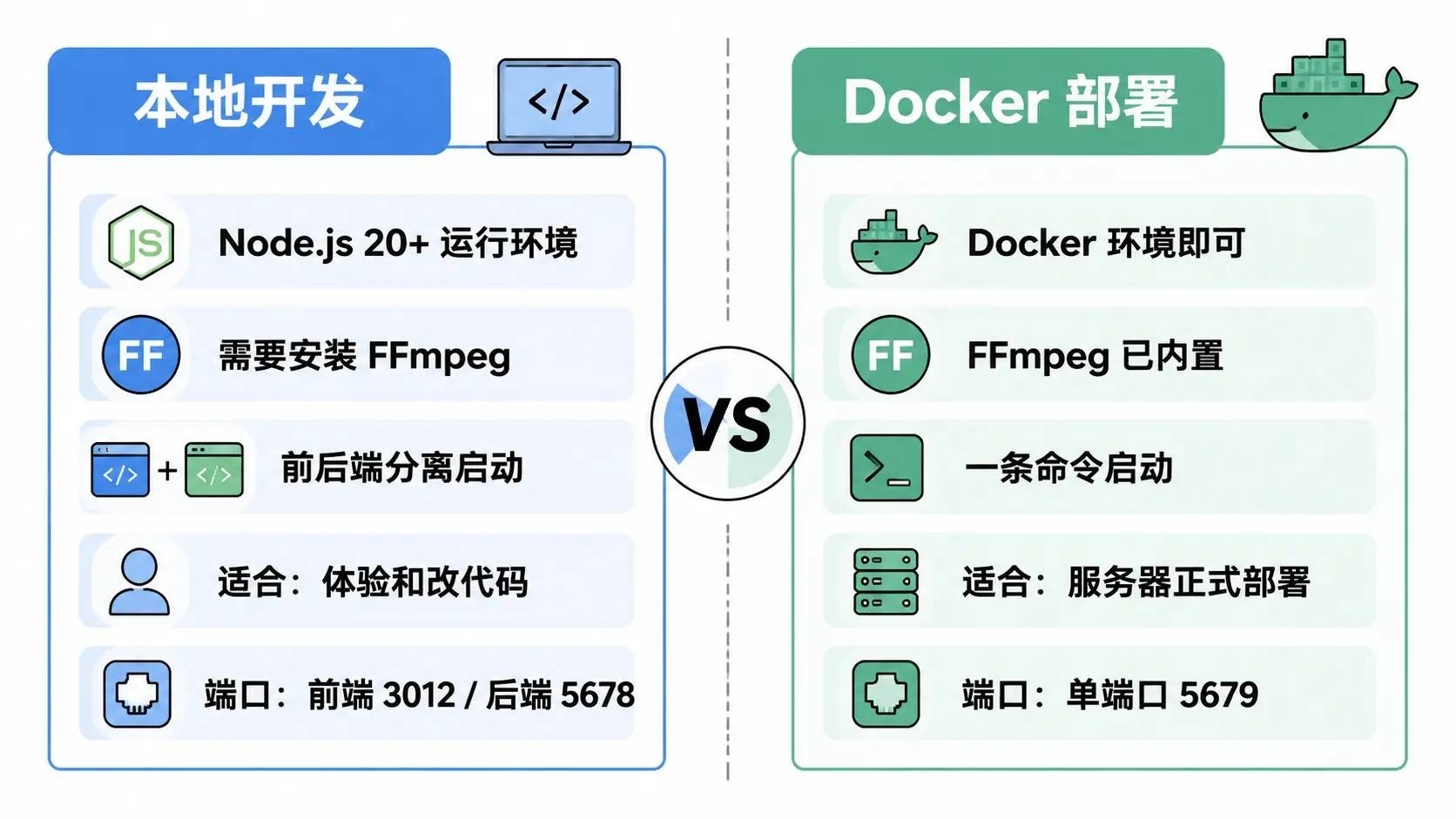
服务器部署(推荐正式使用和团队使用)
如果你要在服务器上跑,用 Docker 一步到位。Docker 镜像内置了 FFmpeg,不需要单独装。
环境要求
| 软件 | 说明 |
|---|---|
| Docker | 容器运行环境 |
| Docker Compose | 编排工具(通常随 Docker 安装) |
部署步骤
- 克隆项目:
git clone https://github.com/chatfire-AI/huobao-drama.git
cd huobao-drama- 复制配置文件:
cp configs/config.example.yaml configs/config.yaml- 启动:
docker compose up -d- 查看日志确认启动成功:
docker compose logs -f- 访问
http://你的服务器IP:5679,看到界面即成功。
Docker 镜像做了什么: 三阶段构建——先构建前端静态文件,再编译后端原生模块(better-sqlite3、sharp),最后打包成单镜像单端口。FFmpeg 已内置。
数据持久化: data/ 目录通过 volume 挂载,容器重建不丢数据。
停止服务: docker compose down
Linux 注意: 如需访问宿主机 Ollama 等服务,docker run 时加 --add-host=host.docker.internal:host-gateway。
连接宿主机 Ollama
Docker 部署后想用宿主机的本地模型:
- 宿主机启动 Ollama,监听所有接口:
export OLLAMA_HOST=0.0.0.0:11434 && ollama serve- 在 Web 界面「设置 → AI 服务配置」填写:
- Base URL:
http://host.docker.internal:11434/v1 - Provider:
openai(Ollama 兼容 OpenAI 接口) - Model: 你下载的模型名,如
qwen2.5:latest
- Base URL:
配置 AI 服务
不管哪种部署方式,启动后都要配置 AI 服务。火宝短剧不绑定单一厂商,所有 API Key 和模型参数在 Web 界面「设置」页面配置。
配置文件说明
configs/config.yaml 控制基础设置(AI 服务在 Web 界面配,这里只配默认厂商):
app:
name: "Huobao Drama API"
version: "1.0.0"
debug: true
language: "zh" # zh(中文) 或 en(英文)
server:
port: 5678 # 后端端口
host: "0.0.0.0"
database:
type: "sqlite"
path: "./data/huobao_drama.db"
storage:
type: "local"
local_path: "./data/storage"
base_url: "http://localhost:5678/static"
ai:
default_text_provider: "openai" # 文本模型默认厂商
default_image_provider: "openai" # 图片生成默认厂商
default_video_provider: "doubao" # 视频生成默认厂商支持的 AI 厂商
文本模型(剧本改写、角色提取、分镜拆解):
| 厂商 | 说明 |
|---|---|
| OpenAI | GPT-4o 等 |
| OpenAI 兼容接口 | 可接 Ollama 本地模型 |
图片生成(角色形象、场景背景、分镜图):
| 厂商 |
|---|
| OpenAI(DALL-E) |
| Gemini |
| MiniMax |
| 火山引擎 |
| 阿里(通义万相) |
| Chatfire |
视频生成(分镜视频片段):
| 厂商 |
|---|
| MiniMax |
| 火山引擎 / Seedance |
| Vidu |
| 阿里 |
TTS 配音:目前仅支持 MiniMax。
省钱建议: 文本处理用 Ollama 本地模型(免费),图片和视频按需选用商业 API。
快捷配置: 项目提供了 API 聚合站点,可以快速完成 API 配置。
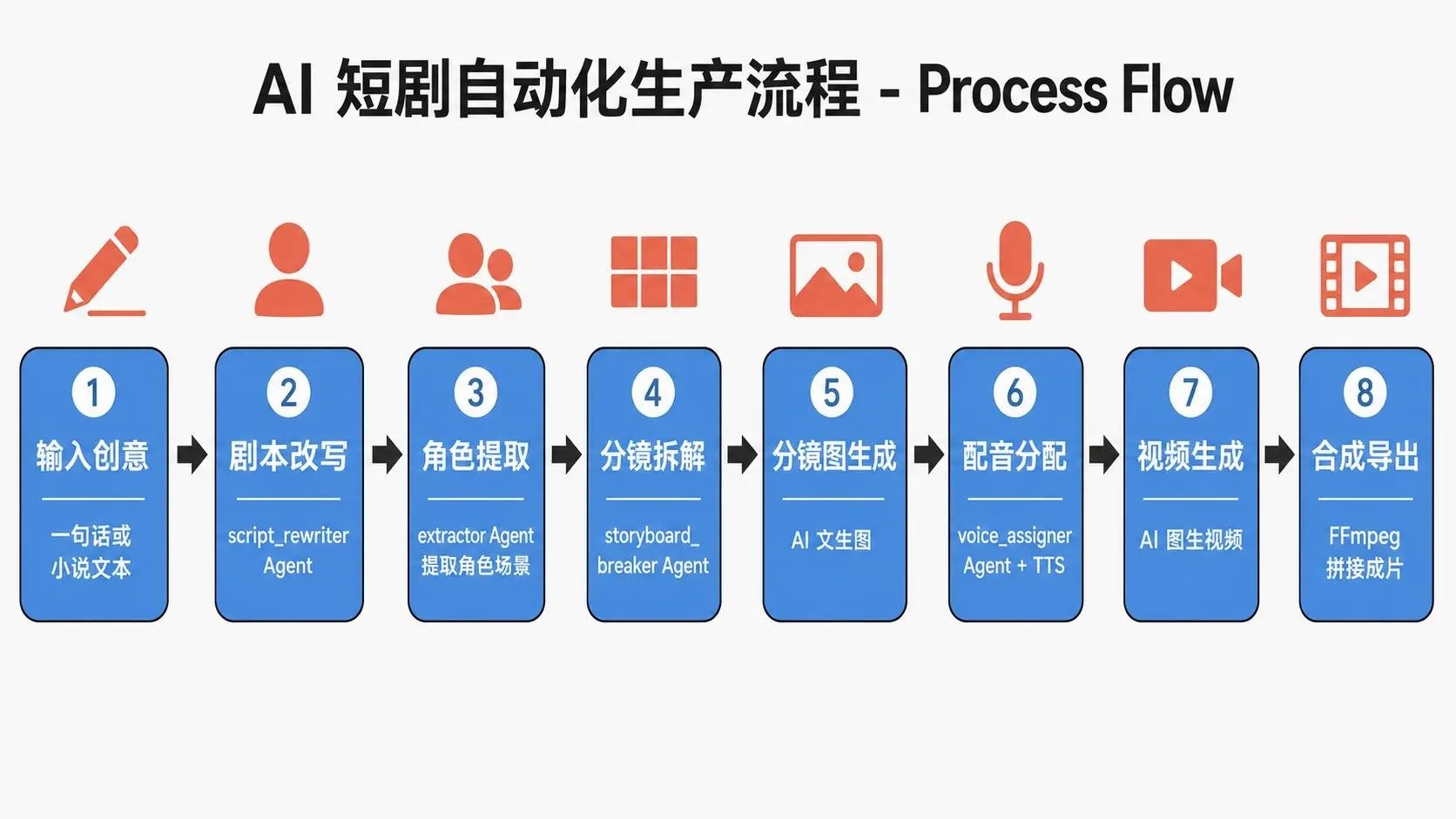
使用流程:从一句话到完整短剧
环境就绪后,按以下 8 步走通。
1. 创建项目,输入创意
打开 Web 界面,创建新短剧项目。你可以:
- 直接输入一句话描述(如"一个都市爱情故事,讲述两个邻居从冤家到恋人的过程")
- 粘贴一段小说文本作为素材
2. AI 改写剧本
script_rewriter Agent 把你的输入改写成标准格式化剧本,包含对话、场景描述、角色动作。自动识别主要角色、场景设置、剧情节奏。
3. 角色提取与形象生成
extractor Agent 从剧本中提取所有角色并去重。然后系统调用 AI 图片生成,为每个角色创建形象图。你可以接受 AI 生成的形象、上传自己的参考图、或调整提示词重新生成。
4. 分镜拆解
storyboard_breaker Agent 把剧本拆解为分镜序列。每个分镜包含场景描述、镜头类型(特写/中景/远景)、角色动作、对话内容。
5. 分镜图生成
系统根据分镜描述调用 AI 图片生成(文生图),为每个分镜生成画面。支持首帧/尾帧模式、宫格图生成与切分、参考图控制角色一致性。
6. 配音分配
voice_assigner Agent 为每个角色自动分配音色。可以试听、手动调整、使用 MiniMax TTS 生成配音。
7. 视频生成
系统调用 AI 视频模型(图生视频),为每个分镜生成视频片段。这一步耗时较长,取决于视频长度和模型速度。
8. 合成与导出
FFmpeg 自动完成:视频片段 + TTS 配音 + 字幕 → 单镜头合成 → 所有镜头拼接 → 导出完整短剧视频。
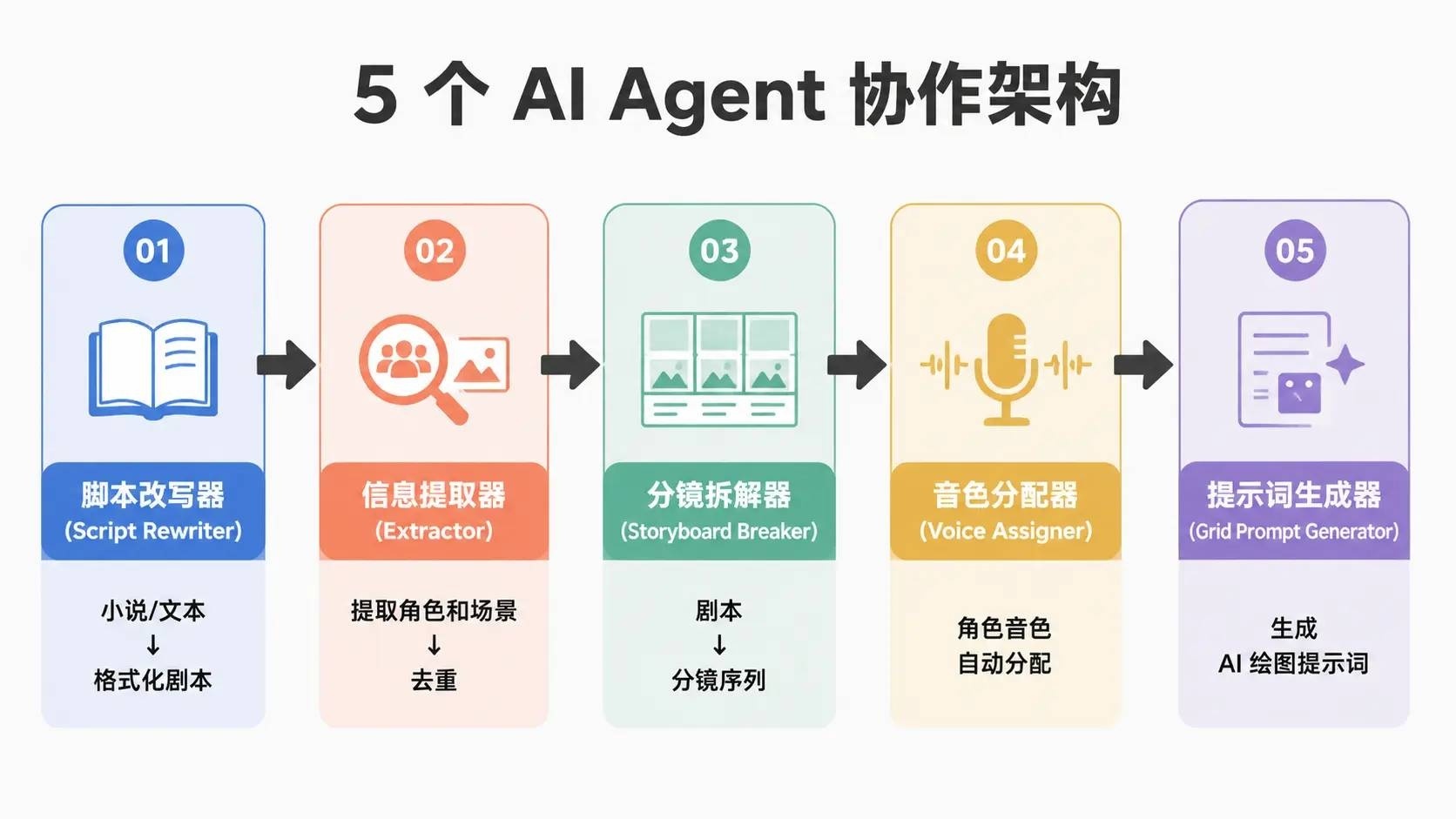
5 个 AI Agent 的分工
整个流程由 5 个 Mastra Agent 协作完成,定义在 skills/ 目录,支持运行时动态加载和扩展:
| Agent | 做什么 | 输入 | 输出 |
|---|---|---|---|
script_rewriter |
小说/文本 → 格式化剧本 | 原始文本 | 标准剧本格式 |
extractor |
提取角色和场景,去重 | 剧本文本 | 角色列表 + 场景列表 |
storyboard_breaker |
剧本 → 分镜序列 | 剧本文本 | 分镜列表 |
voice_assigner |
角色音色自动分配 | 角色列表 | 音色分配方案 |
grid_prompt_generator |
生成图片提示词 | 角色/场景/分镜描述 | AI 绘图提示词 |
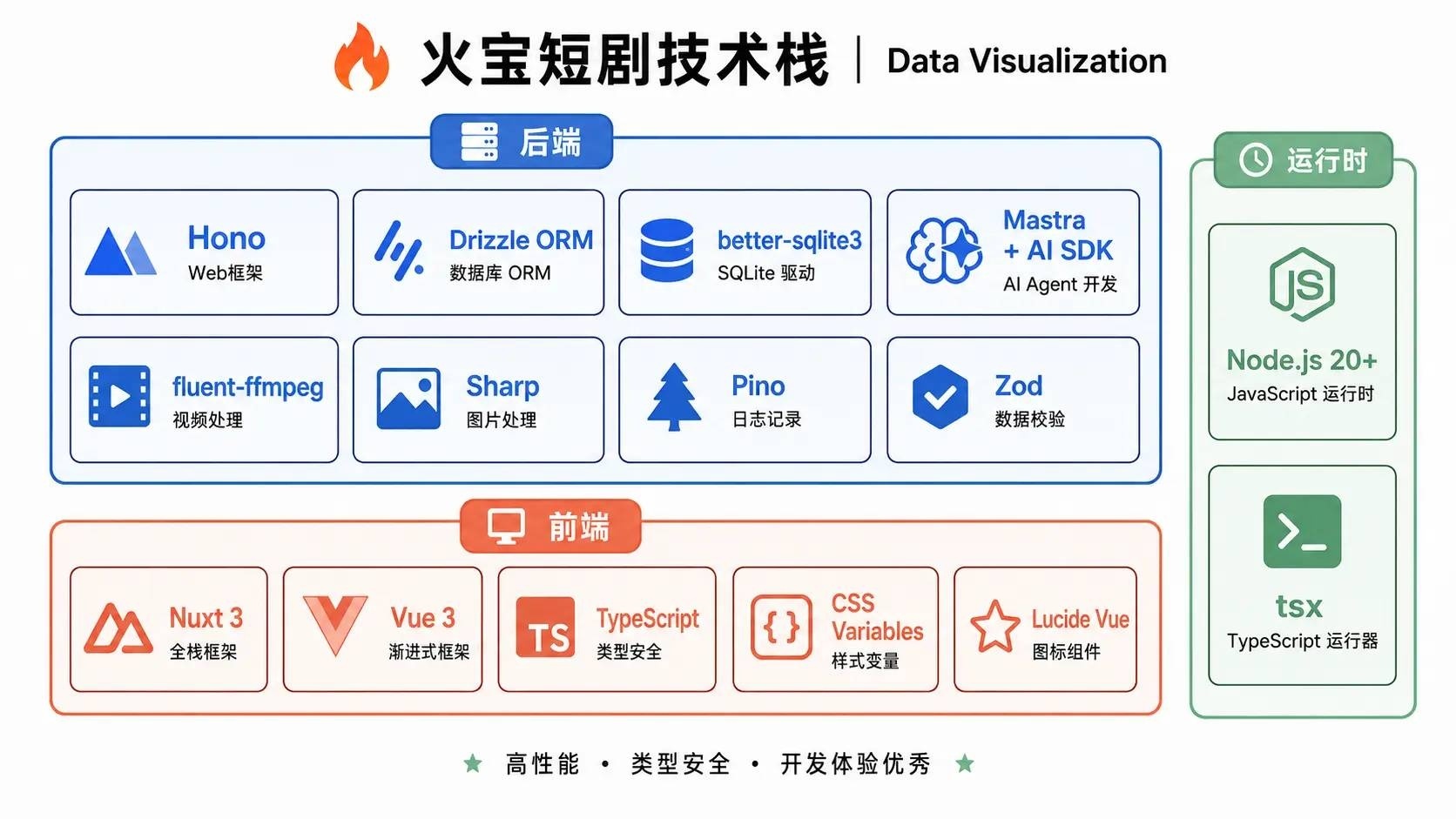
技术栈一览
二次开发或贡献代码前了解:
后端(backend/src/):
| 组件 | 技术 | 用途 |
|---|---|---|
| Web 框架 | Hono | HTTP 路由和中间件 |
| ORM | Drizzle ORM | 数据库操作 |
| 数据库 | better-sqlite3 | SQLite 驱动 |
| AI Agent | Mastra + AI SDK | Agent 编排和 LLM 调用 |
| 视频处理 | fluent-ffmpeg | FFmpeg 绑定 |
| 图片处理 | Sharp | 裁剪、转码 |
| 日志 | Pino | 结构化日志 |
| 校验 | Zod | 数据验证 |
前端(frontend/):
| 组件 | 技术 |
|---|---|
| 框架 | Nuxt 3(SPA 模式) |
| 语言 | Vue 3 + TypeScript |
| 样式 | 纯 CSS + CSS Variables(暗色主题) |
| 图标 | Lucide Vue |
项目用 tsx 直接运行 TypeScript,开发时 tsx watch 支持热重载。
常见问题
Docker 容器怎么访问宿主机的 Ollama?
使用 http://host.docker.internal:11434/v1 作为 Base URL。宿主机 Ollama 需监听 0.0.0.0:
export OLLAMA_HOST=0.0.0.0:11434 && ollama serveLinux 用户用 docker run 时加 --add-host=host.docker.internal:host-gateway。
FFmpeg 找不到?
确保 FFmpeg 在 PATH 中,运行 ffmpeg -version 验证。Docker 部署已内置,不需要单独装。
前端连不上后端?
开发模式检查 frontend/nuxt.config.ts 里的代理配置,确认后端端口一致。
数据库表没创建?
后端首次启动自动建表,检查日志确认初始化成功。数据目录需要写权限。
AI 生成质量不理想?
文本模型建议用 GPT-4o 级别以上,Ollama 本地模型至少用 Qwen2.5 7B。图片和视频质量取决于所选厂商和模型。
注意
项目 License 是 CC BY-NC-SA 4.0,个人学习和研究免费,商用需联系团队获取授权。