Reddit 上有个帖子火了。一个 ChatGPT Plus 用户说他以为深度研究的 10 次额度是按计费周期重置的,结果一口气用了 5 次之后才发现——是按 30 天算的,不是按账单日。剩下一个月,他只有 5 次深度研究可用。
另一个帖子更惨。一个团队花了 3 个月开发浏览器自动化 Agent,给全公司做演示。模拟环境一切正常,切到真实网站,MFA 弹窗直接把 Agent 卡死了。反爬检测识别出自动化工具,验证码一个接一个。3 个月的工作在 30 秒内崩溃。
这不是段子。这是 2025-2026 年 AI Agent 开发者每天遇到的真实场景。搜索限制、反爬拦截、动态页面渲染失败——这三座大山挡在每个需要让 Agent "上网"的开发者面前。
但问题不在于这些障碍存在,而在于多数人根本没意识到:你可以不依赖官方搜索,自己搭一套。
一、三座大山:Agent 搜索能力的真实痛点
痛点 1:官方搜索额度用得太快
这不是错觉,数据说话:
| 产品 | 搜索限制 | 限制周期 | 来源 |
|---|---|---|---|
| ChatGPT Plus 深度研究 | 10 次 | 每 30 天(非计费周期) | Reddit r/ChatGPT 用户确认 |
| ChatGPT Pro 深度研究 | 25 次 | 每 30 天 | @testingcatalog X 推文 |
| ChatGPT Free 深度研究 | 5 次(轻量版) | 每月 | PCMag 报道 |
| Claude Code WebSearch | 未公开的月度上限 | 5 小时滑动窗口 | Anthropic Help Center |
| Perplexity Pro | ~600 次 Pro Search | 每天 | Perplexity 官方 |
一个典型的深度调研场景——"帮我调研 AI Agent 搜索工具市场"——可能需要 30-50 次搜索,加上内容提取和对比,轻松超过任何一个产品的单次限制。
Claude Code 的用户在 GitHub Issues 里频繁报告这个问题(issue #29579):即使订阅了 Max,仍然在正常使用中遭遇 Rate Limit。解决方式?要么等重置,要么额外按 API 用量付费。
痛点 2:反爬拦截越来越狠
2026 年的数据不容乐观:
- 51% 的互联网流量来自机器人,网站反爬措施因此持续升级
- AI 爬虫流量同比增长 400%,Cloudflare 等防护服务加大了拦截力度
- Cloudflare 拦截 94% 的自动化爬取请求——这意味着你用普通 HTTP 请求抓取内容,10 次里有 9 次会被拦住
Reddit r/AI_Agents 上那个"3 个月开发,30 秒崩溃"的帖子不是个例。评论区里到处是类似的经历:
"Site detects it as bot, throws captcha. Our stealth mode was useless against their anti bot measures."
反爬的升级速度比 Agent 框架的更新速度快得多。你不能假设"今天能抓的页面明天还能抓"。
痛点 3:JavaScript 渲染是隐形杀手
这可能是最被低估的痛点。
2026 年,绝大多数现代网站依赖 JavaScript 渲染内容。但 AI 爬虫和多数搜索 API 在抓取页面时不执行 JavaScript。结果就是:你拿到了页面的 HTML,但里面是空的——所有内容都由 JavaScript 动态加载。
LinkedIn 上的一篇分析指出:"如果爬虫在抓取时不执行或完全处理 JavaScript,重要内容可能不会出现在抓取的版本中。"
这意味着:
- 单页应用(SPA)的内容你可能完全抓不到
- "加载更多"按钮、无限滚动、筛选器背后的内容被完全忽略
- 很多看起来"正常"的页面,实际上对你的 Agent 是不可见的
Firecrawl 的博客总结了这个困境:传统搜索 API 返回 URL 和两行摘要,要拿到完整内容你得自己 fetch、处理 JavaScript 渲染、提取文本、转 Markdown——每一步都可能失败。
二、正确的思路:搭建自己的搜索管线
认清了三大痛点,解决思路就很清楚了:
搜索(Search) → 提取(Extract) → 降级(Fallback)
↓ ↓ ↓
获取 URL 列表 把网页变成文本 被拦时用备用方案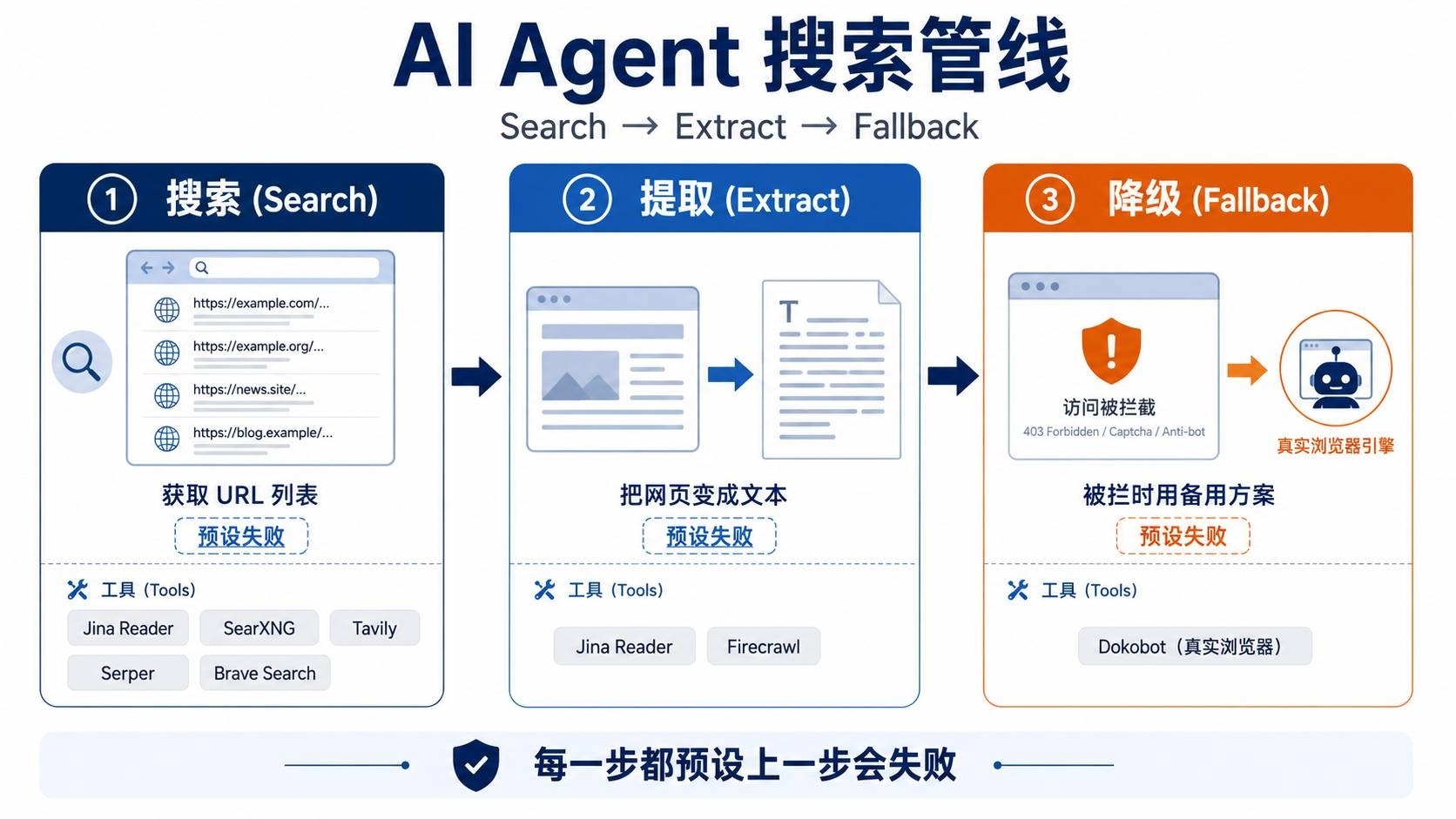
注意第三步:不是"结构化",而是降级。因为反爬和 JavaScript 渲染问题太普遍了,你的管线必须预设"第一步会失败"。
下面按这三个环节,逐一介绍经过验证的工具。
三、搜索环节:5 个经过验证的选择
3.1 Jina Reader Search — 搜索 + 提取一步到位
官方地址:jina.ai/reader | API Key 申请:jina.ai | GitHub:github.com/jina-ai/reader
为什么先说它:Jina Reader 不只是搜索工具,它搜索后自动获取 top 5 结果并提取内容——搜索和提取在同一个 API 调用中完成。这是市面上唯一一个"一步到位"的方案。
# 搜索 + 自动提取内容
curl "https://s.jina.ai/AI+agent+search+tools"
-H "Authorization: Bearer YOUR_JINA_API_KEY"免费额度:
- 无 API key:20 RPM
- 免费申请 API key:200 RPM
- 对个人调研来说,200 RPM 基本等于"不限量"
社区真实评价(Reddit r/mcp):
"You get 1M credits and then it's $50 for enough credits (1B) that I'll probably never run out for my needs."
局限:
- 对某些技术类查询,搜索质量不如 Google 直接搜索
- 不支持自定义搜索引擎选择
3.2 SearXNG — 唯一真正无限制的搜索方案
官方地址:searxng.org | Docker Hub:hub.docker.com/r/searxng/searxng | MCP Server:pypi.org/project/searxng-mcp
它是什么:开源元搜索引擎。一次查询同时调用 Google、Bing、Brave、DuckDuckGo 等多个引擎,合并去重后返回结果。
为什么值得花时间部署:
- 完全免费,零调用限制——这是唯一不受任何额度约束的搜索方案
- 自托管,数据不出你的服务器
- 多引擎聚合,结果覆盖面比任何单一引擎都广
# Docker 一行部署
docker run -d -p 8080:8080 searxng/searxng
# 调用 API
curl "http://localhost:8080/search?q=AI+agent+search+tools&format=json"社区真实评价(Reddit r/mcp):
"I am running private SearXNG instances (one local and one in the cloud)... Free. Fully private. Works like a charm."
"SearXNG since it's self hosted you won't have a dime to pay and that's a big positive point."
局限:
- 需要自己维护 Docker 服务
- 只返回搜索结果元数据(URL、标题、摘要),不包含页面内容
- 部分引擎的结果可能被上游反爬限制
适合谁:有服务器或本地 Docker 环境、月搜索量大、对成本零容忍的开发者。
3.3 Tavily — Agent 生态的默认选择
官方地址:tavily.com | API Key 申请:app.tavily.com | 文档:docs.tavily.com
它是什么:专为 AI Agent 设计的搜索 API。LangChain、CrewAI 等框架把它作为默认搜索工具。
核心优势:
- 返回 LLM 直接可消费的结构化内容(不需要自己解析 HTML)
search_depth参数控制质量/延迟:basic 1 credit,advanced 2 credit- 官方 MCP Server 可直接集成到 Claude Code
from tavily import TavilyClient
client = TavilyClient(api_key="your_key")
results = client.search("AI agent search tools", search_depth="basic")定价:
- 1,000 次/月免费
- Pay-as-you-go: $0.008/credit
- 5K 搜索/月约 $32,50K 约 $392
社区真实评价(Reddit r/AI_Agents):
"Tavily is probably the most agent-friendly option right now, specifically because it returns structured results designed for LLM consumption rather than raw HTML."
注意:搜索结果中的 content 字段返回的是摘要,不是完整页面文本。要拿完整内容需设置 include_raw_content: true 或调用 /extract 端点。
3.4 Serper — 性价比最高的 SERP API
官方地址:serper.dev | API Key 申请:serper.dev | 文档:serper.dev/api-reference
它是什么:直接返回 Google 搜索结果数据的 API。干净、快、便宜。
为什么值得了解:
- 2,500 次/月免费
- 50K 搜索仅 $47.50/月——同样量级在 SerpAPI 要 $1,247.50,差距 26 倍
curl "https://google.serper.dev/search"
-H "X-API-KEY: your_key"
-d '{"q":"AI agent search tools"}'局限:只返回 SERP 元数据(标题、URL、摘要),不含页面内容。需要配合内容提取工具使用。
3.5 Brave Search API — Claude Code 内置后端
官方地址:brave.com/search/api | API Key 申请:brave.com/search/api | MCP Server:GitHub 搜索 "brave-search-mcp"
Claude Code 的 WebSearch 工具背后就是 Brave Search。如果你用 MCP 方式接入 Brave Search API,就有了不受 Claude Code 额度限制的独立搜索通道。
- 独立索引,不依赖 Google/Bing
- 免费层级:2,000 次/月
- MCP Server 广泛可用
四、内容提取环节:当搜索只给了你 URL
搜索给了 URL 列表,但 Agent 要的是内容。这个环节要解决两个问题:把网页变成 Markdown 文本,以及当普通方式被拦住时的降级方案。
4.1 Jina Reader — 提取环节的免费首选
官方地址:jina.ai/reader | 使用方式:直接在 URL 前加
https://r.jina.ai/
# 提取任意 URL 为 Markdown
curl "https://r.jina.ai/https://example.com/article"
-H "Authorization: Bearer YOUR_JINA_API_KEY"关键能力:
- 自动处理 JavaScript 渲染——对 SPA 页面也能提取内容
- 输出纯净 Markdown,LLM 直接可读
- 免费使用(200 RPM 有 key)
- 同一个 API key 覆盖搜索和提取
什么时候会失败:需要登录的页面(Reddit 登录后内容、Medium 会员文章)、有强反爬的页面(Cloudflare 高级别防护)。
4.2 Firecrawl — 专业级网页爬取
官方地址:firecrawl.dev | API Key 申请:firecrawl.dev | MCP Server:github.com/firecrawl/firecrawl-mcp-server
当 Jina Reader 处理不了的页面(复杂的 JavaScript 渲染、需要批量爬取),Firecrawl 提供更专业的解决方案:
- Scrape(单页)、Batch Scrape(批量)、Crawl(整站爬取)
- 官方 MCP Server
- 支持 JavaScript 渲染和结构化数据提取
定价:500 免费 credits,付费从 $16/月起。
注意:社区中有用户反映开源版稳定性不足,部分人已切换到 Crawl4AI(同样开源,但更轻量)。
4.3 Dokobot — 反爬场景的最后一道防线
官方地址:dokobot.ai | Chrome 扩展:Chrome Web Store | 安装指南:dokobot.ai/zh-CN/install
这是本文最值得你记住的工具之一。
当 Jina Reader 返回 403、当 Firecrawl 拿到空白内容、当 Cloudflare 把你拦在门外——Dokobot 用你本地的真实浏览器访问页面,能处理那些让所有 API 都束手无策的网站。因为你用的是真正的 Chrome,登录墙、JS 密集型应用、机器人检测——统统不是问题。
安装分两步:
# 第一步:安装 Chrome 扩展(支持 Chrome、Edge、Brave、Arc)
# 从 Chrome Web Store 一键安装,链接见上方
# 第二步:安装 CLI
npm i -g @dokobot/cli@latestChrome 扩展是核心——它在本地浏览器和 CLI 之间建立 Bridge,让 CLI 能读取你浏览器中的任何页面。两步都完成后即可使用:
dokobot read --local "https://www.reddit.com/r/AI_Agents/comments/xxx/"它能处理的场景:
- Reddit 帖子(需要登录才能看完整内容)
- Twitter/X 动态内容
- 知乎、小红书等内容平台
- 任何被 Cloudflare 或类似服务保护的页面
- 需要登录的 Medium 会员文章
输出:纯净 Markdown,不下载图片(只提取文本,速度快)。
定价:本地模式(Local)免费、无限制、无需登录。还有 Remote 模式用于远程浏览器控制,属于付费功能。
降级策略建议:
正常流程:Jina Reader → 成功 → 用结果
第一降级:Jina 失败(403/空白) → Firecrawl → 成功 → 用结果
最终降级:Firecrawl 也失败 → Dokobot → 用真实浏览器提取五、JavaScript 渲染问题:一个被忽视的隐性成本
回到前面提到的痛点 3。这个问题太重要了,值得单独说清楚。
现实情况:2026 年,大量网站的"真实内容"只存在于 JavaScript 执行后的 DOM 中。如果抓取工具不执行 JavaScript,你拿到的就是一个空壳。
各工具的 JavaScript 处理能力:
| 工具 | JS 渲染 | 能力 |
|---|---|---|
| Jina Reader | 自动处理 | 能处理大部分 SPA |
| Firecrawl | 支持 | 需要配置 |
| Crawl4AI | 支持(Playwright) | 需要配置 |
| Dokobot | 原生支持 | 真实浏览器引擎,最可靠 |
| 普通 HTTP 抓取 | 不支持 | 只能拿到静态 HTML |
实操建议:如果你的 Agent 需要频繁抓取现代网站(React/Vue/Angular SPA),在管线中至少保留一个支持 JavaScript 渲染的工具。Dokobot 或 Firecrawl 是首选。
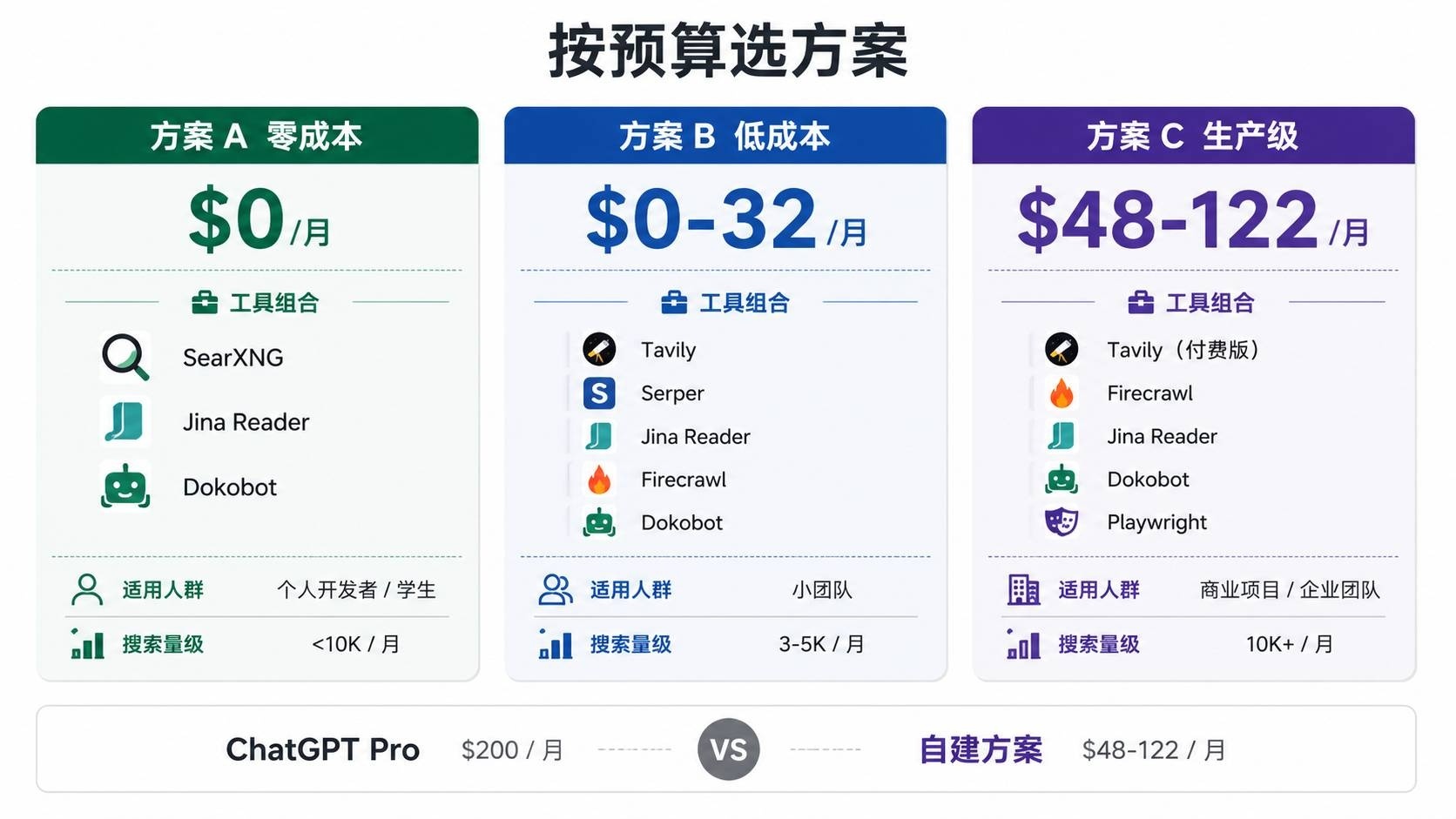
六、3 套实操方案:按预算选
方案 A:零成本方案
| 环节 | 工具 | 成本 | 说明 |
|---|---|---|---|
| 搜索 | SearXNG 自托管 | $0 | Docker 一行部署 |
| 搜索 + 提取 | Jina Reader(免费 key) | $0 | 200 RPM |
| 反爬降级 | Dokobot | $0 | 本地运行 |
| 总计 | $0/月 | 适合月搜索量 < 10K |
适合:个人开发者、学生、有 Docker 环境的用户。
方案 B:低成本方案
| 环节 | 工具 | 成本 | 说明 |
|---|---|---|---|
| 搜索 | Tavily 免费额度 + Serper 免费额度 | $0 | 3,500 次/月免费 |
| 搜索 + 提取 | Jina Reader | $0 | 200 RPM |
| 专业爬取 | Firecrawl 免费额度 | $0 | 500 credits |
| 反爬降级 | Dokobot | $0 | 本地运行 |
| 总计 | $0-32/月 | 超出免费额度后按量付费 |
适合:小团队、重度个人用户。免费额度可以覆盖每月 3-5K 搜索。
方案 C:生产级方案
| 环节 | 工具 | 成本 |
|---|---|---|
| 搜索 | Tavily 付费 | ~$32-72/月 |
| 提取 | Firecrawl + Jina Reader | ~$16-50/月 |
| 反爬降级 | Dokobot + Playwright | $0 |
| 总计 | $48-122/月 |
适合:月搜索量 10K+ 的团队或商业项目。这个成本远低于 ChatGPT Pro 的 $200/月,但搜索能力不受任何限制。
七、MCP Server:即插即用,不用写代码
如果你用的是 Claude Code、Cursor 等 MCP 兼容环境,好消息是——上面提到的多数工具都有现成的 MCP Server。装上就能用,不需要写一行 API 调用代码。
| MCP Server | 功能 | 安装链接 |
|---|---|---|
| Tavily | 搜索 + 提取 | tavily.com |
| Brave Search | Web 搜索 | brave.com/search/api |
| Jina Reader | 搜索 + 提取 | jina.ai/reader |
| Exa | 语义搜索 | exa.ai |
| Firecrawl | 网页爬取 | github.com/firecrawl/firecrawl-mcp-server |
| SearXNG | 元搜索 | pypi.org/project/searxng-mcp |
在 Claude Code 中,MCP Server 安装后直接成为 Agent 可调用的工具。搜索、提取、降级——Agent 自己决定什么时候用什么工具。
八、定价对比:50K 搜索/月的真实成本
同样的 50K 搜索/月,不同方案的月成本:
| 工具 | 50K 搜索/月成本 | 免费额度 | 单价/搜索 |
|---|---|---|---|
| SearXNG 自托管 | $0 | 无限 | $0 |
| Serper | $47.50 | 2,500 次 | $0.001 |
| DataForSEO | $99 | $1 试用 | $0.002 |
| Exa | $245 | 1,000 次 | $0.005 |
| Tavily | $392 | 1,000 次 | $0.008 |
| SerpAPI | $1,247.50 | 100 次 | $0.025 |
数据来源:BuildMVPFast AI Search API 定价对比(2026 年 4 月更新)
价格差距达 26 倍(Serper vs SerpAPI),但价格高不等于适合你。关键判断:你需要的是搜索元数据(标题+URL+ 摘要)还是完整页面内容?
- 只需要元数据 → Serper($0.001/搜索)最划算
- 需要完整内容 → Tavily($0.008/搜索)或 Jina Reader(免费)更合适
- 需要无限搜索 → SearXNG($0)是唯一选择
九、检查清单:你的搜索管线完整吗
搭建搜索能力前,用这个清单逐项检查:
- 搜索环节:至少有一个可用的搜索工具(推荐 SearXNG 或 Tavily)
- 提取环节:至少有一个内容提取工具(推荐 Jina Reader)
- 降级策略:当主工具被拦时有备选(推荐 Dokobot)
- JS 渲染:管线中至少有一个工具能处理 JavaScript(Jina Reader 或 Dokobot)
- 额度监控:知道每个工具的免费额度上限
- 成本预估:根据预估搜索量选择方案 A/B/C
- MCP 集成:如果用 Claude Code,已安装相关 MCP Server
总结:官方搜索限制不是无解的。ChatGPT Plus 深度研究每月 10 次够干什么?Claude Code WebSearch 用完就得等重置?自己搭一套搜索管线——搜索、提取、降级三个环节组合起来——就能彻底摆脱这些限制。
从零成本的 SearXNG + Jina Reader + Dokobot 开始。等你验证了管线可行性,再按需升级到付费方案。别再等下月额度重置了。