
你说“把这篇 NYT 做成播客”,它就给你一个 MP3
qiaomu-anything-to-notebooklm(GitHub)是一个 Claude Code Skill,干的事情很简单:你给它任何内容,告诉它你要什么格式,它帮你搞定。
你:把这篇 The Information 文章生成播客 https://www.theinformation.com/articles/...
AI:✅ 检测付费墙 → Googlebot UA 绕过 → 获取全文 → 上传 NotebookLM → 生成播客
📁 /tmp/article_podcast.mp3(8 分钟)
你:这期小宇宙播客做成 PPT https://xiaoyuzhoufm.com/episode/...
AI:✅ Get笔记 API 转写音频 → 上传 → 生成 PPT
📁 /tmp/podcast_slides.pdf(25 页)
你:深度分析这本电子书 /Users/joe/Books/sapiens.epub
AI:✅ 提取 EPUB 全文 → 上传 → 三轮递进提问(12个问题)
📁 /tmp/sapiens_analysis.json背后靠的是 Google NotebookLM 的内容生成能力,这个 Skill 做的是把“找到内容 → 绕过限制 → 上传 → 生成 → 下载”这条链路完全自动化。
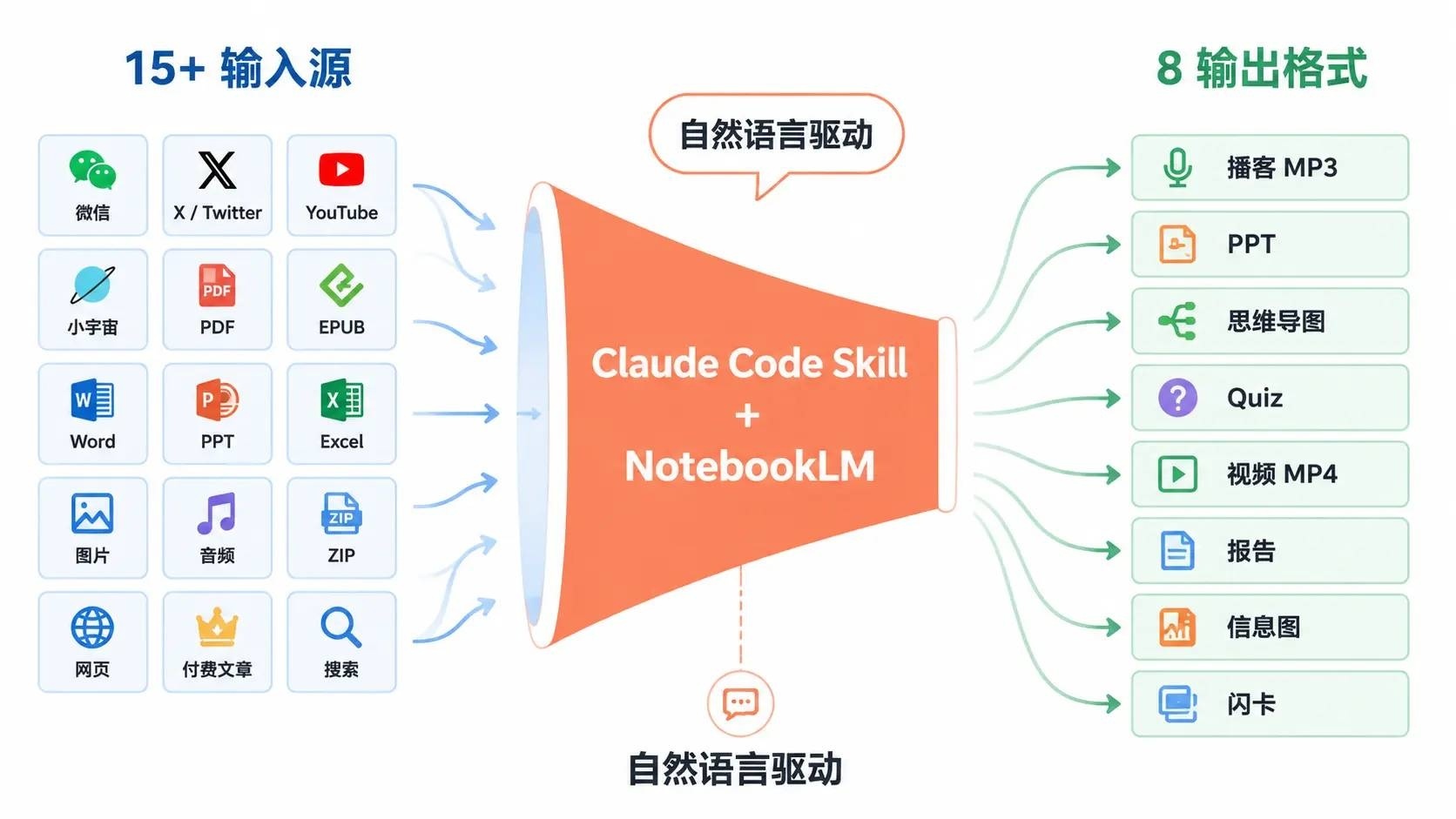
15 种内容源进,8 种格式出
输入和输出是两个维度。你可以从 15+ 种来源拿内容,再选 8 种格式之一生成。
支持的输入源:
| 类别 | 来源 | 获取方式 |
|---|---|---|
| 社交媒体 | 微信公众号、X/Twitter | MCP 浏览器模拟 / 代理级联 |
| 视频/音频 | YouTube、小宇宙、喜马拉雅、B 站 | NotebookLM 原生 / Get 笔记 API 转写 |
| 网页 | 任意公开网页、300+ 付费网站 | 直接抓取 / 付费墙绕过 |
| 文档 | PDF、EPUB、Markdown、Word、PPT、Excel | markitdown / ebooklib 转换 |
| 其他 | 图片(OCR)、音频(转录)、ZIP(批量)、纯文本 | markitdown 处理 |
可以生成的格式:
| 格式 | 用途 | 说“什么”触发 |
|---|---|---|
| 播客 MP3 | 通勤路上听 | “生成播客”、“做成音频” |
| PPT(PDF) | 团队分享 | “做成 PPT”、“生成幻灯片” |
| 思维导图 | 理清结构 | “画个思维导图” |
| Quiz | 自测掌握 | “出题”、“生成 Quiz” |
| 视频 MP4 | 可视化展示 | “做个视频” |
| 报告 | 深度分析 | “生成报告” |
| 信息图 | 数据可视化 | “做个信息图” |
| 闪卡 | 记忆巩固 | “做成闪卡” |
可以混合多种来源——“把这篇文章、这个视频和这个 PDF 一起做成 PPT”,Skill 会创建一个 Notebook,把三个 Source 都加进去,基于全部内容生成。
300+ 付费网站自动绕过
这是最有争议也最实用的功能。fetch_url.sh 实现了 6 层级联降级策略:
Level 1: 代理服务(r.jina.ai / defuddle.md)
↓ 失败
Level 2: Googlebot UA + X-Forwarded-For(~50 站,SEO 白名单)
↓ 失败
Level 3: 通用绕过(UA 伪装 + Referer 伪装 + AMP 页面)
↓ 失败
Level 4: archive.today 存档
↓ 失败
Level 5: Google Cache
↓ 失败
Level 6: agent-fetch 本地浏览器引擎核心原理是搜索引擎爬虫白名单——大多数新闻网站为了让 Google 索引全文,会给爬虫(Googlebot/Bingbot)返回完整内容,只是对普通浏览器显示付费墙。fetch_url.sh 利用这一点,伪装请求头获取全文。
覆盖范围包括 NYT、WSJ、Bloomberg、Washington Post、FT、The Economist、WIRED、The New Yorker、The Atlantic、Medium、MIT Tech Review、SCMP 等 300+ 站点。
每个层级都有内容有效性检查:行数 > 8、字符数 > 500、过滤“Access Denied” / “404” / 登录墙等常见错误页面。还会检测付费墙特征词(“subscribe to continue”、“remaining free articles”等),如果检测到就自动降级到下一层策略。
项目声明技术参考自 Bypass Paywalls Clean,仅限个人学习研究使用。
深度分析模式:让 NotebookLM 替你读完全书
普通模式是“上传内容 → 生成格式”,深度分析模式是另一种玩法:上传内容后,自动生成 12 个递进式问题,逐一向 NotebookLM 提问,收集答案输出结构化 JSON。
三轮递进策略设计:
| 轮次 | 问题数 | 目的 |
|---|---|---|
| 第一轮:概览与框架 | 4 | 核心主题、整体结构、核心论点、颠覆性内容 |
| 第二轮:深度挖掘 | 5 | 论证逻辑、关键证据、内部矛盾、核心洞察、尖锐批评 |
| 第三轮:综合与反刍 | 3 | 认知改变、行动指南、推荐理由 |
关键设计点:NotebookLM 在同一会话中保持上下文,所以第二轮提问时 NotebookLM 已经“读过”第一轮的问答,第三轮时又叠加了第二轮的理解。这不是 12 个独立问题,而是三层递进的认知升级。
问题设计根据内容类型自适应——书籍侧重论证逻辑与文本细读,视频侧重论据拆解与立场分析,文章侧重叙事结构与作者视角。所有问题都加了“完全基于已上传的文档内容回答”的前缀,防止 NotebookLM 触发网络搜索。
输出可以直接写入飞书文档(--to-feishu 参数),格式化为飞书 Markdown 并通过 lark-cli 自动创建。
# 深度分析一本电子书
python main.py ./book.epub --deep-analysis
# 深度分析 + 自动创建飞书文档
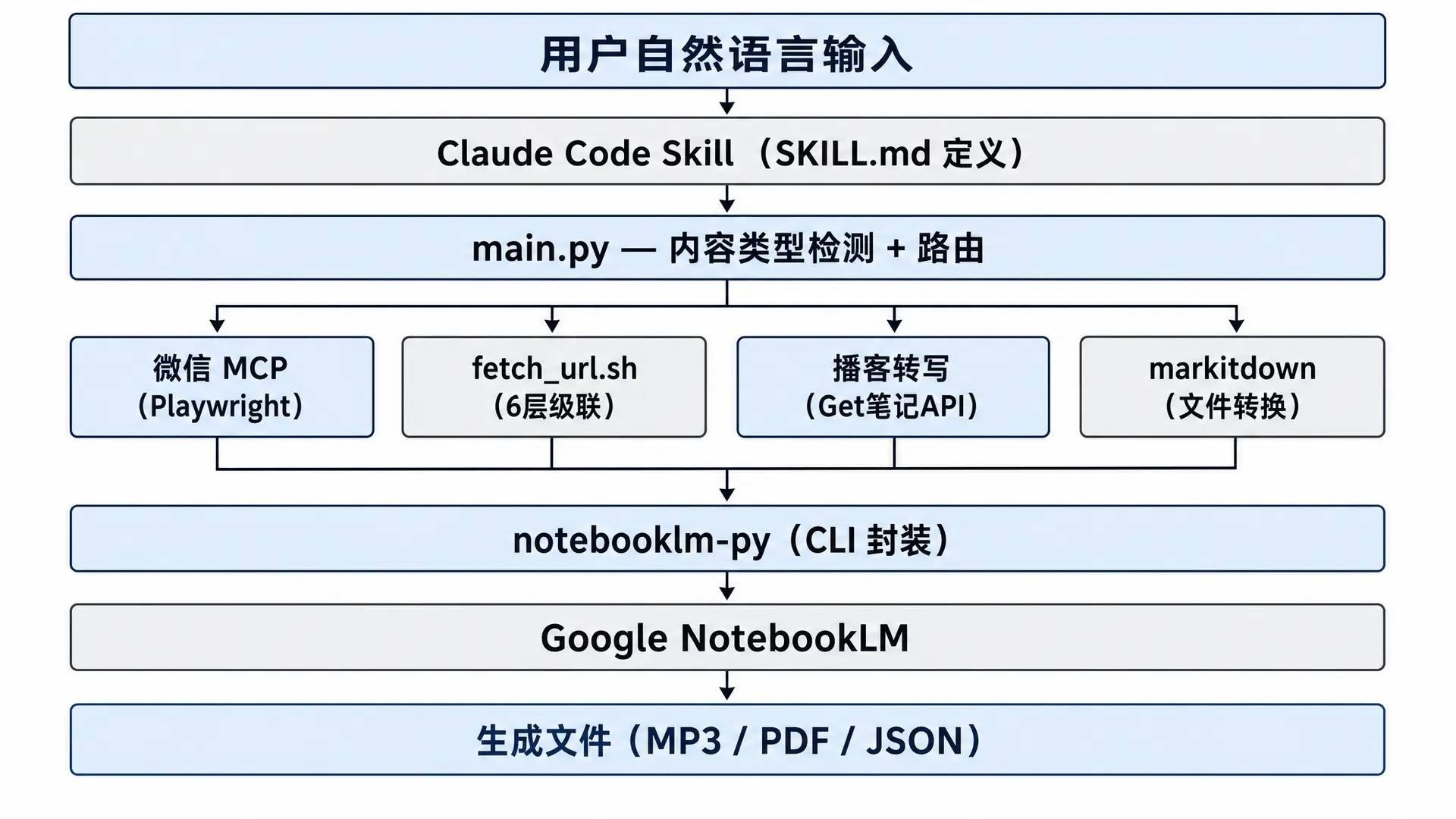
python main.py ./book.epub --deep-analysis --to-feishu技术架构:为什么能做到这些
整个项目的技术栈很轻:
用户自然语言输入
↓
Claude Code Skill(SKILL.md 定义)
↓
main.py — 内容类型检测 + 路由
↓
┌──────────┬──────────┬──────────┬──────────┐
│ 微信 MCP │ fetch_url │ 播客转写 │ markitdown│
│ Playwright│ 6层级联 │ Get笔记API│ 文件转换 │
└────┬─────┴────┬─────┴────┬─────┴────┬─────┘
└──────────┴──────────┴──────────┘
↓
notebooklm-py(CLI 封装)
↓
Google NotebookLM
↓
生成文件(MP3/PDF/JSON...)几个有意思的工程选择:
- YouTube 视频不下载字幕,直接把 URL 丢给 NotebookLM——NotebookLM 原生支持 YouTube 链接,自动提取字幕和元数据,省掉中间步骤
- EPUB 用 Python ebooklib + BeautifulSoup 提取文本,不用 Calibre——避免 Calibre 的架构依赖问题
- 付费墙绕过用 Shell 脚本而不是 Python——curl 更轻量,方便在命令行直接调试每一层策略
- 播客转写用 Get 笔记 API 而不是 Whisper——30 秒轮询转写状态,2-5 分钟完成,不需要本地 GPU
- 微信抓取通过 MCP 服务器(Playwright 浏览器模拟)——单独的 MCP 进程,不污染主流程
3 步安装,5 分钟上手
# 1. 克隆到 Claude skills 目录
cd ~/.claude/skills/
git clone https://github.com/joeseesun/qiaomu-anything-to-notebooklm
cd qiaomu-anything-to-notebooklm
# 2. 一键安装所有依赖
./install.sh
# 3. 认证 NotebookLM(只需一次)
notebooklm login
notebooklm list # 验证成功可选配置:播客转写(小宇宙/喜马拉雅/B 站)
通过 Get 笔记 API 实现音频转文字,需要配置 API Key:
export GETNOTE_API_KEY="your_api_key"
export GETNOTE_CLIENT_ID="your_client_id"API Key 获取地址:Get 笔记开放平台
安装完成后运行 ./check_env.py 可以做 13 项环境检查,确保所有组件就绪。
前置条件只要两样:Python 3.9+ 和 Git。其他依赖 install.sh 一键搞定。
值得注意的几个边界
- 依赖非官方 API:notebooklm-py 是对 NotebookLM 网页版的 CLI 封装,不是 Google 官方 API,如果 Google 改版可能会失效
- 频率限制:微信抓取每次请求间隔 > 2 秒,NotebookLM 最多 3 个并发生成任务
- 内容长度:最短约 500 字,最长约 50 万字,1000-10000 字效果最佳
- 生成时间:播客 2-5 分钟,PPT 1-3 分钟,视频 3-8 分钟
- 付费墙绕过的法律边界:技术原理基于搜索引擎白名单,不破解任何加密。项目明确声明仅限个人学习研究