 如果你把 Browser Use 理解成"加了 AI 的 Playwright",那从一开始就看错了方向。
如果你把 Browser Use 理解成"加了 AI 的 Playwright",那从一开始就看错了方向。
Playwright 的思路是:你写好每一步——点哪个元素、填什么值、等什么条件——浏览器严格执行。Browser Use 的思路是:你描述目标,LLM 看页面、推理、决策、操作,自己决定怎么完成。
这不是"更聪明",而是根本不同的自动化范式。一个是确定性编程,一个是不确定性推理。理解这个差异,是判断 Browser Use 到底适不适合你的前提。
Agent Loop:四步循环的具体实现
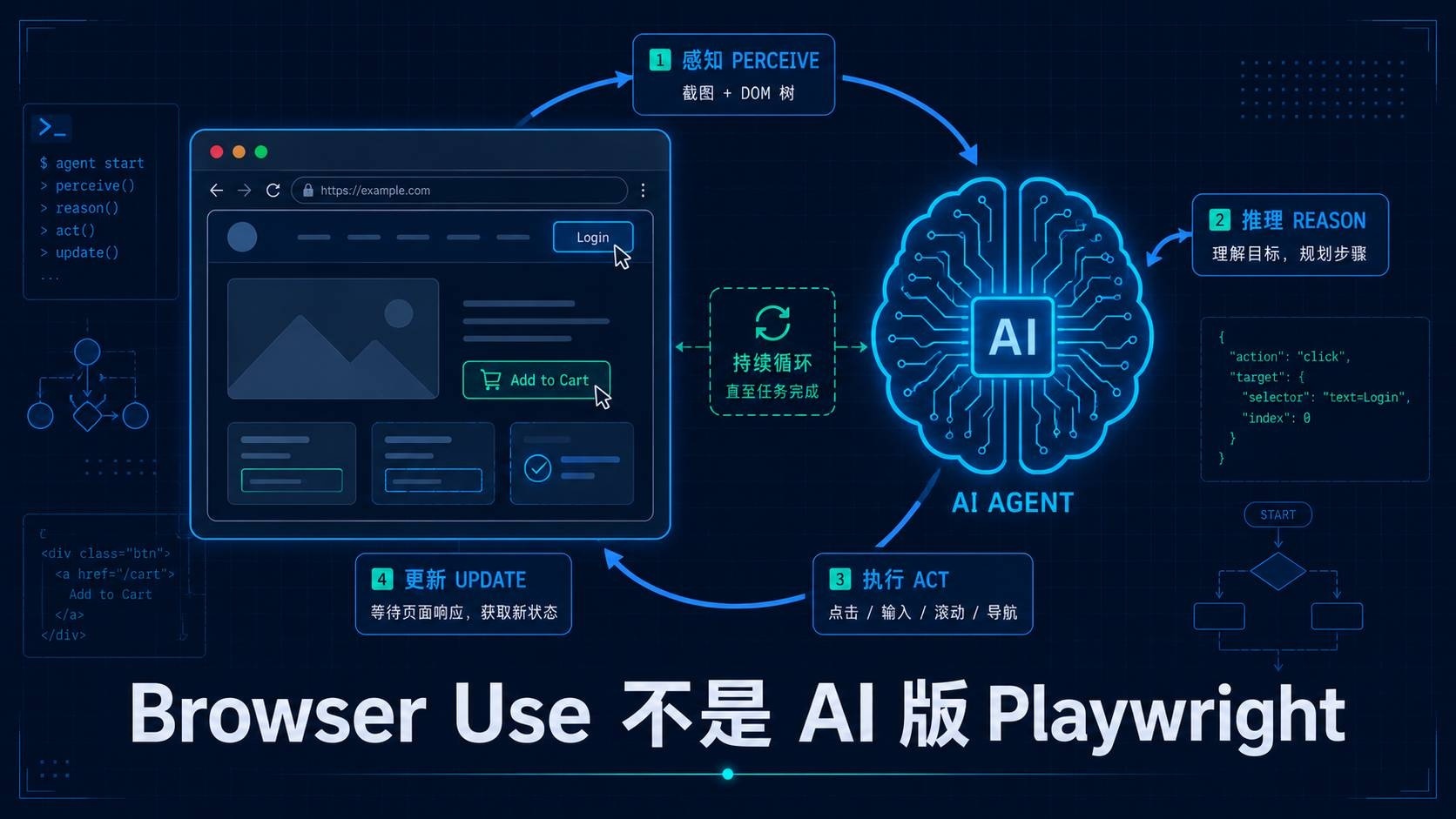
Browser Use 的核心是一个闭环控制结构:
状态感知 → LLM推理 → 动作执行 → 状态更新 → 循环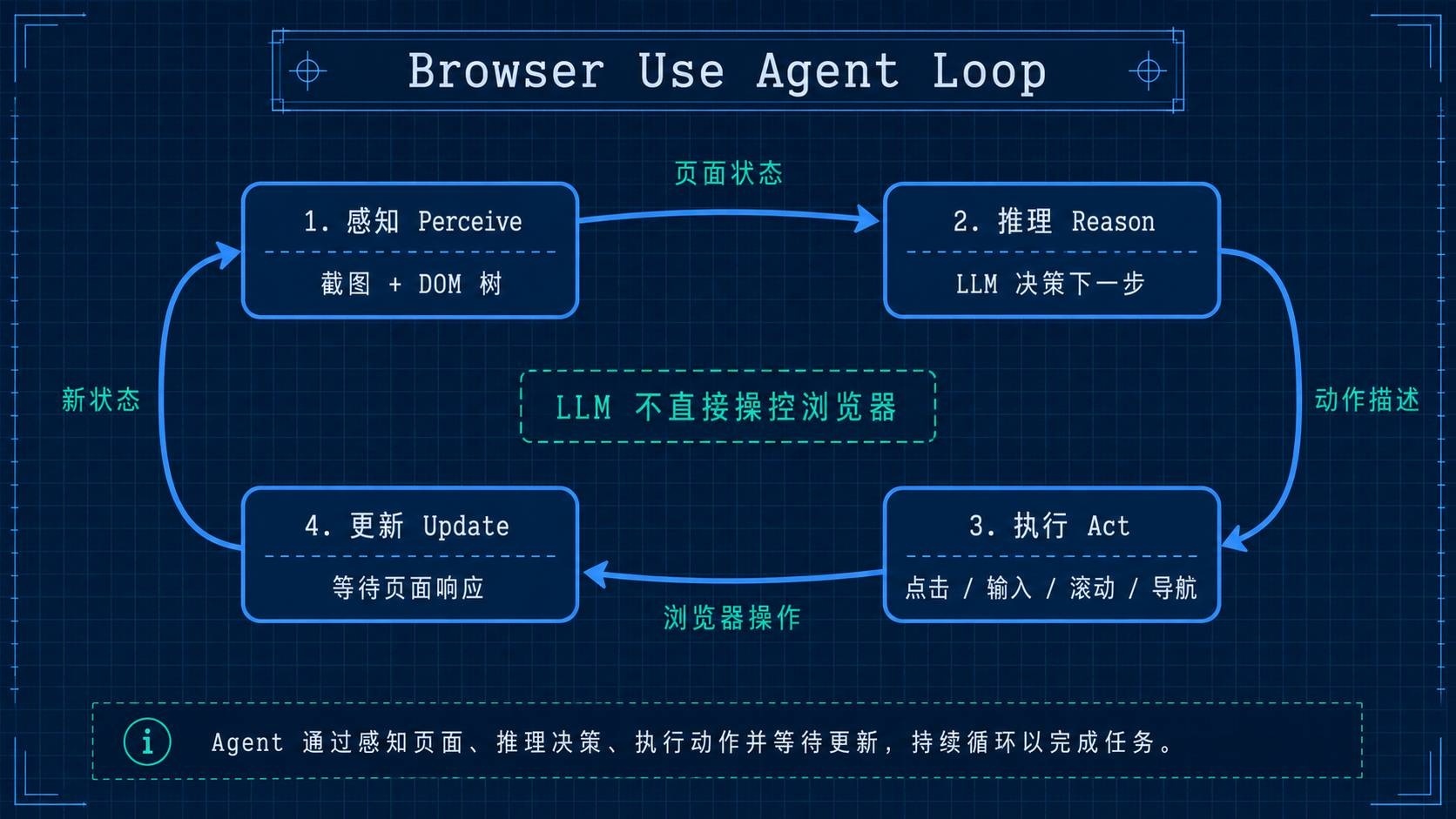
具体来说,每一步循环做了四件事:
- 感知(Perceive):捕获当前页面状态,包含截图和 DOM 树两路信号
- 推理(Reason):LLM 接收页面状态 + 任务描述 + 历史上下文,输出下一步动作
- 执行(Act):Browser Use 将 LLM 输出的动作翻译成浏览器操作(点击、输入、滚动、导航、切换标签等)
- 更新(Update):等待页面响应,回到步骤 1
关键架构决策:LLM 不直接操控浏览器。 LLM 输出的是结构化的动作描述("点击索引为 5 的元素"),Browser Use 的执行层负责把这个描述翻译成 Playwright API 调用。
这种设计的好处是 LLM 和浏览器解耦——你可以换掉 LLM、换掉浏览器引擎,甚至换成 Cloud 托管浏览器,Agent Loop 本身不变。
一个最简的 Agent 代码看起来是这样:
from browser_use import Agent, ChatBrowserUse
agent = Agent(
task="Find the number of stars of the browser-use repo",
llm=ChatBrowserUse(model='bu-2-0'),
)
agent.run_sync()三行有效代码,背后是完整的 Agent Loop 在运转。task 是自然语言描述,llm 是推理引擎,Agent 自己决定去哪个网站、搜索什么、点击什么、什么时候算完成。
双通道感知:为什么需要两种"看"页面的方式
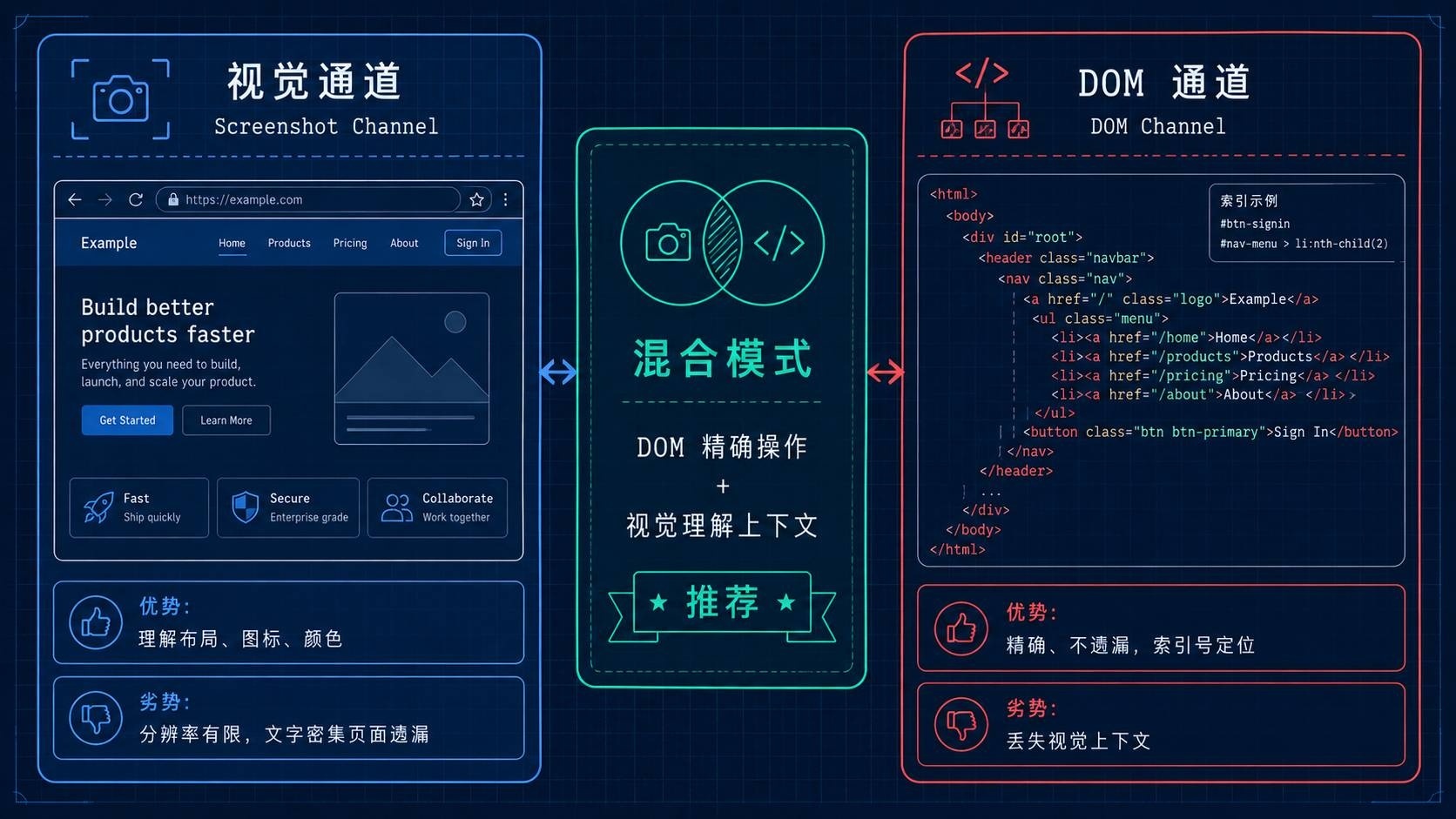
Browser Use 的感知层同时使用两种信号源:
视觉通道(Screenshot):截取当前页面截图,传给支持视觉的 LLM。优点是和人眼看到的一致,能理解布局、图标、颜色等视觉信息。缺点是分辨率有限,文字密集页面容易遗漏细节。
DOM 通道(DOM Structure):提取页面的 DOM 树,经过压缩和标注后传给 LLM。每个可交互元素被标注一个索引号(如 [5]提交按钮),LLM 通过索引号指代元素。优点是精确、不遗漏,缺点是丢失视觉上下文。
两者可以独立使用,也可以同时启用。实际测试表明,双通道混合模式在复杂页面上表现最好——DOM 保证精确操作,视觉帮助理解上下文。
Trade-off 提示:双通道意味着每步循环要处理更多 token,延迟更高、成本更高。如果你的任务在结构化页面上(比如后台管理系统),纯 DOM 模式可能更高效。
10+ LLM 接入层:延迟加载与统一抽象
Browser Use 的 LLM 接入层设计得相当克制。看一下 __init__.py 的实现:
_LAZY_IMPORTS = {
'ChatOpenAI': ('browser_use.llm.openai.chat', 'ChatOpenAI'),
'ChatGoogle': ('browser_use.llm.google.chat', 'ChatGoogle'),
'ChatAnthropic': ('browser_use.llm.anthropic.chat', 'ChatAnthropic'),
'ChatBrowserUse': ('browser_use.llm.browser_use.chat', 'ChatBrowserUse'),
'ChatGroq': ('browser_use.llm.groq.chat', 'ChatGroq'),
'ChatOllama': ('browser_use.llm.ollama.chat', 'ChatOllama'),
# ... 还有 ChatMistral, ChatAzureOpenAI, ChatOCIRaw, ChatLiteLLM, ChatVercel
}两个值得注意的架构选择:
- 延迟加载(Lazy Import):所有 LLM 客户端都是延迟导入的。你只用
ChatOpenAI,就不会加载anthropic、google-genai等依赖 - 统一接口:所有 Chat 类都遵循相同的接口协议,Agent 不关心底层是哪个 LLM。一行代码切换模型,不需要改 Agent 逻辑
ChatBrowserUse:自研模型的性价比逻辑
Browser Use 推出了自研模型 ChatBrowserUse(bu 系列),定价是:
| 项目 | 价格 |
|---|---|
| Input tokens | $0.20 / 1M |
| Cached input tokens | $0.02 / 1M |
| Output tokens | $2.00 / 1M |
对比其他模型在 Browser Use 内部 benchmark 上的表现,以 Tasks per $1 为指标:
| 模型 | Tasks/$1 |
|---|---|
| ChatBrowserUse (bu) | 53 |
| Gemini Flash | 19 |
| Claude Sonnet 4.5 | 2 |
ChatBrowserUse 的性价比是 Claude Sonnet 4.5 的 26.5 倍。
但这里要诚实说明:这个 benchmark 是 Browser Use 自己测的(browser-use/benchmark),测试集是 100 个真实浏览器任务。模型是专门针对浏览器自动化场景微调的,在通用 NLP 任务上不一定有优势。
如果你用 Browser Use 做的就是浏览器自动化任务,这个性价比数据是可信的。
性能基准:不回避真实数据
谈技术选型,不谈数据就是空谈。
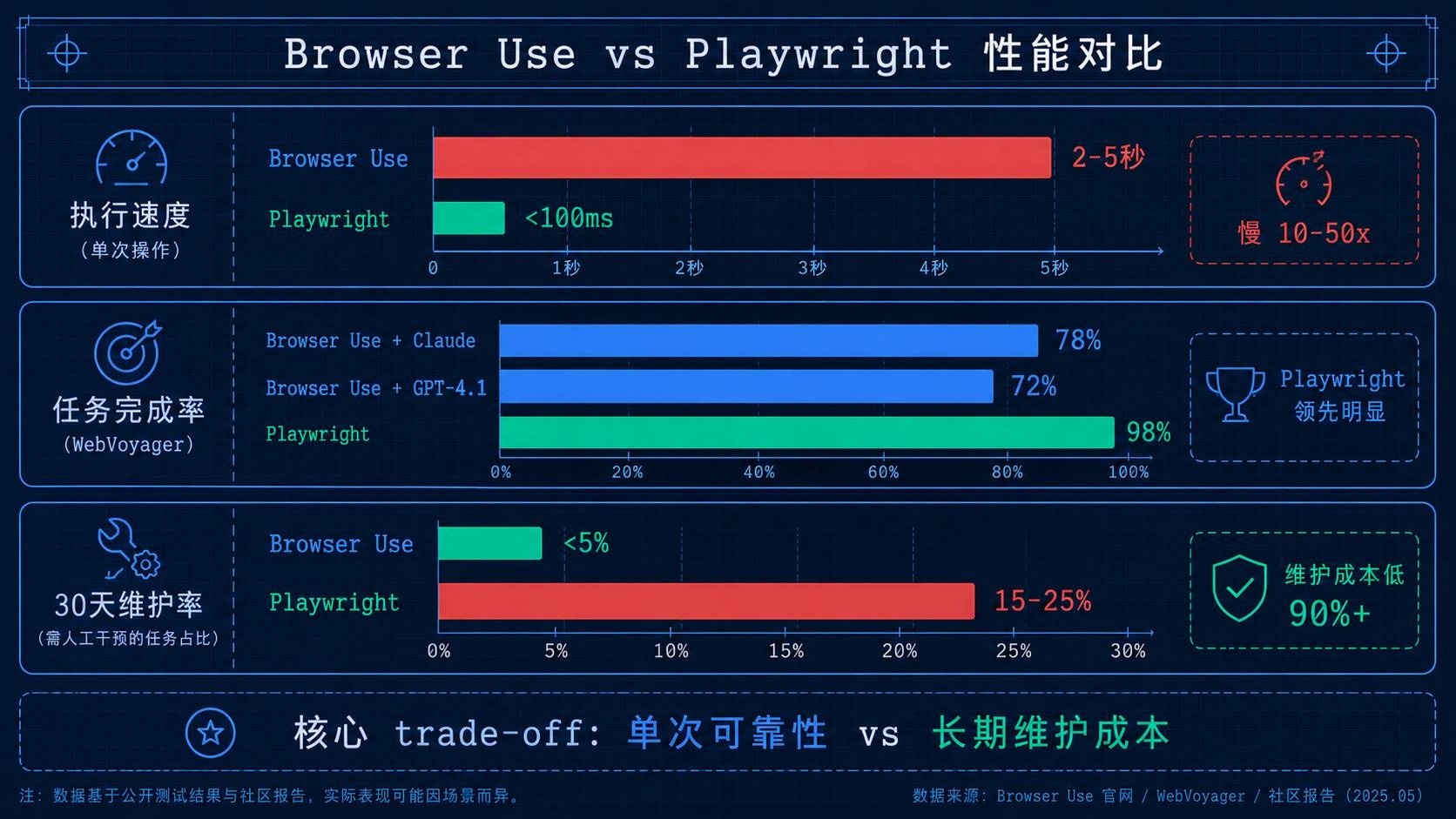
执行速度
每个 AI 动作都需要一次 LLM 推理调用(发送 DOM/截图 → 接收动作),导致 AI 自动化在绝对速度上远慢于传统方案:
| 操作类型 | Browser Use | Playwright |
|---|---|---|
| 简单点击 | 2-5 秒 | <100ms |
| 表单填写 (5 字段) | 10-30 秒 | <500ms |
| 数据提取 (单页) | 5-15 秒 | <200ms |
| 多步骤任务 (10 步) | 30-90 秒 | 1-5 秒 |
Browser Use 比 Playwright 慢 10-50 倍。这是架构差异决定的——LLM 推理延迟不是优化能消除的。
任务完成率
在 WebVoyager 基准测试(标准 Web Agent 导航真实网站的测试)上:
- Browser Use + Claude Opus 4.6:~78%
- Browser Use + GPT-4.1 Vision:~72%
- Playwright(手写脚本):~98%
Browser Use 的单次完成率确实低于 Playwright。
维护成本——这才是关键
上面的数据只看了一面。另一面是 30 天维护负担:
| 工具 | 30 天内需要修复的比例 |
|---|---|
| Playwright 脚本 | 15-25%(选择器失效) |
| Browser Use | <5%(需调整提示词) |
AI 自动化的核心 trade-off:单次可靠性与长期维护成本的反向关系。 Playwright 每次执行都可靠,但 UI 一变就得改代码;Browser Use 单次可能失败,但几乎不需要因为 UI 变化而维护。
如果你的页面一周变一次,这个 trade-off 就很明显了。
单任务成本
按 GPT-4.1 定价估算:
| 场景 | 成本 |
|---|---|
| 简单任务 (5 步) | $0.02-0.08 |
| 复杂任务 (20 步) | $0.08-0.30 |
用 ChatBrowserUse 的话,成本会低很多。但每天跑 10,000 个提取任务,LLM 费用仍然在 $200-3000/天。规模化场景下需要认真评估。
CLI 和 Claude Code Skill:不只是 Python 库
除了 Python API,Browser Use 还提供了几个值得关注的入口。
CLI 持久化浏览器
browser-use open https://example.com # 导航
browser-use state # 查看可交互元素
browser-use click 5 # 点击索引5的元素
browser-use type "Hello" # 输入文本
browser-use screenshot page.png # 截图
browser-use close # 关闭CLI 的特点是浏览器会话是持久的——命令之间浏览器不关闭,对于调试和快速迭代很实用。
Claude Code Skill
如果你用 Claude Code(Anthropic 的 CLI 工具),可以安装 Browser Use Skill,让 AI 编程助手直接操控浏览器:
mkdir -p ~/.claude/skills/browser-use
curl -o ~/.claude/skills/browser-use/SKILL.md
https://raw.githubusercontent.com/browser-use/browser-use/main/skills/browser-use/SKILL.md编程 Agent 不仅能写代码,还能打开浏览器验证结果。
模板系统
uvx browser-use init --template default # 最简上手
uvx browser-use init --template advanced # 全配置示例
uvx browser-use init --template tools # 自定义工具示例模板降低了上手门槛,但 advanced 模板的配置项相当多——Browser Use 的灵活性是有学习曲线的。
限制与适用边界
Browser Use 在以下场景不适合:
1. 高频确定性操作
每秒执行 100 次点击?用 Playwright。LLM 推理延迟是秒级的,不是毫秒级的。
2. 成本敏感的批量任务
每天 100 万次价格爬取?LLM 费用会让预算爆炸。确定性场景下 Playwright 成本为零。
3. 合规和审计要求 100% 确定性
金融交易、医疗系统、合规报表——任何需要每一步都可预测、可审计的场景,不应该引入 LLM 的不确定性。
4. 简单页面、结构稳定
如果你的目标页面是内部管理系统,DOM 结构三个月不变,手写 Playwright 脚本的成本反而更低。
实践建议:什么时候该用它
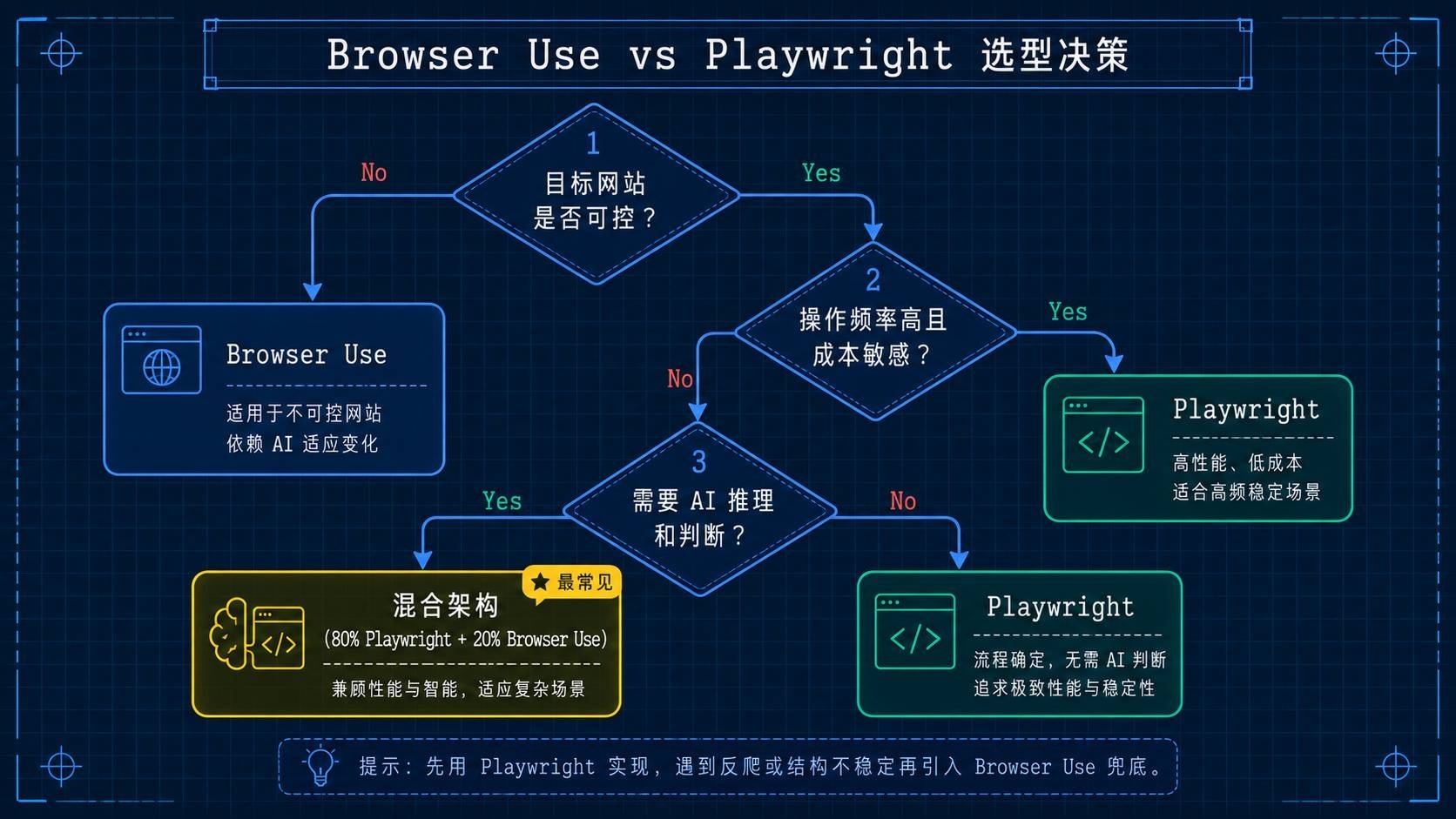
基于上面的分析,判断标准是:
用 Browser Use 的场景:
- 目标网站不是你控制的(第三方网站、竞品页面、公共平台)
- UI 频繁变化或 A/B 测试多
- 任务本身需要推理和判断("找最便宜的"而不是"点第三个按钮")
- 快速原型验证,不确定目标页面的结构
- 构建更大的 AI Agent 系统的一部分
继续用 Playwright 的场景:
- 你自己的网站或你可控的页面
- CI/CD 自动化测试
- 高频、大批量、成本敏感的操作
- 需要精确可审计的操作链
混合使用(实际最常见):
用 Playwright 处理 80% 的确定性步骤,只在需要 AI 理解能力的 20% 步骤引入 Browser Use。这种混合架构正在成为生产环境的主流选择。
关键数据速查
| 指标 | 数值 |
|---|---|
| GitHub Stars | 93,187+ |
| 开源协议 | MIT |
| 当前版本 | v0.12.6 |
| 支持 LLM | 10+ 种提供商 |
| 自研模型性价比 | 53 tasks/$1 |
| WebVoyager 完成率 | 72-78%(视模型) |
| 30 天维护率 | <5% |
| CLI 别名 | browser-use / bu / browseruse / browser |
| Python 版本要求 | >=3.11 |
进一步阅读
- GitHub 仓库 — 源码和 examples 目录
- Browser Use 文档 — 开源库和 Cloud 文档
- Browser Use Benchmark — 100 个真实浏览器任务的基准测试
- Desktop App — 开源桌面浏览器应用